
Athena を介して別アカウントの S3 バケットのデータを QuickSight で可視化する
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
コーヒーが好きな emi です。
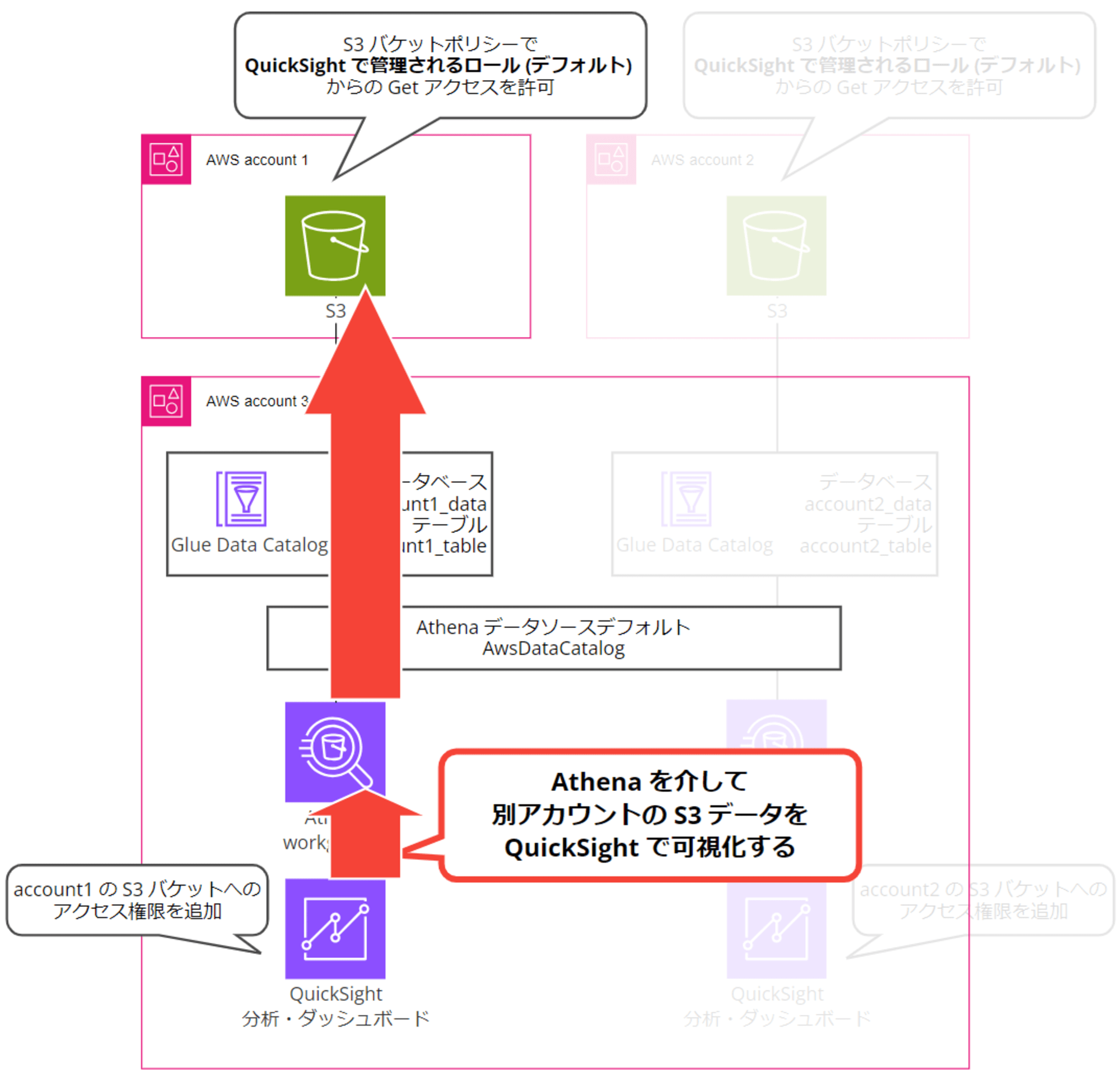
複数の AWS アカウントに存在する S3 バケットのデータを、一つの AWS アカウントの QuickSight から Athena 経由で可視化する方法を検証しました。手順や設定内容を記載します。
前提条件
色々リソースの分け方があるようなのですが、今回は以下の図のような構成にしました。
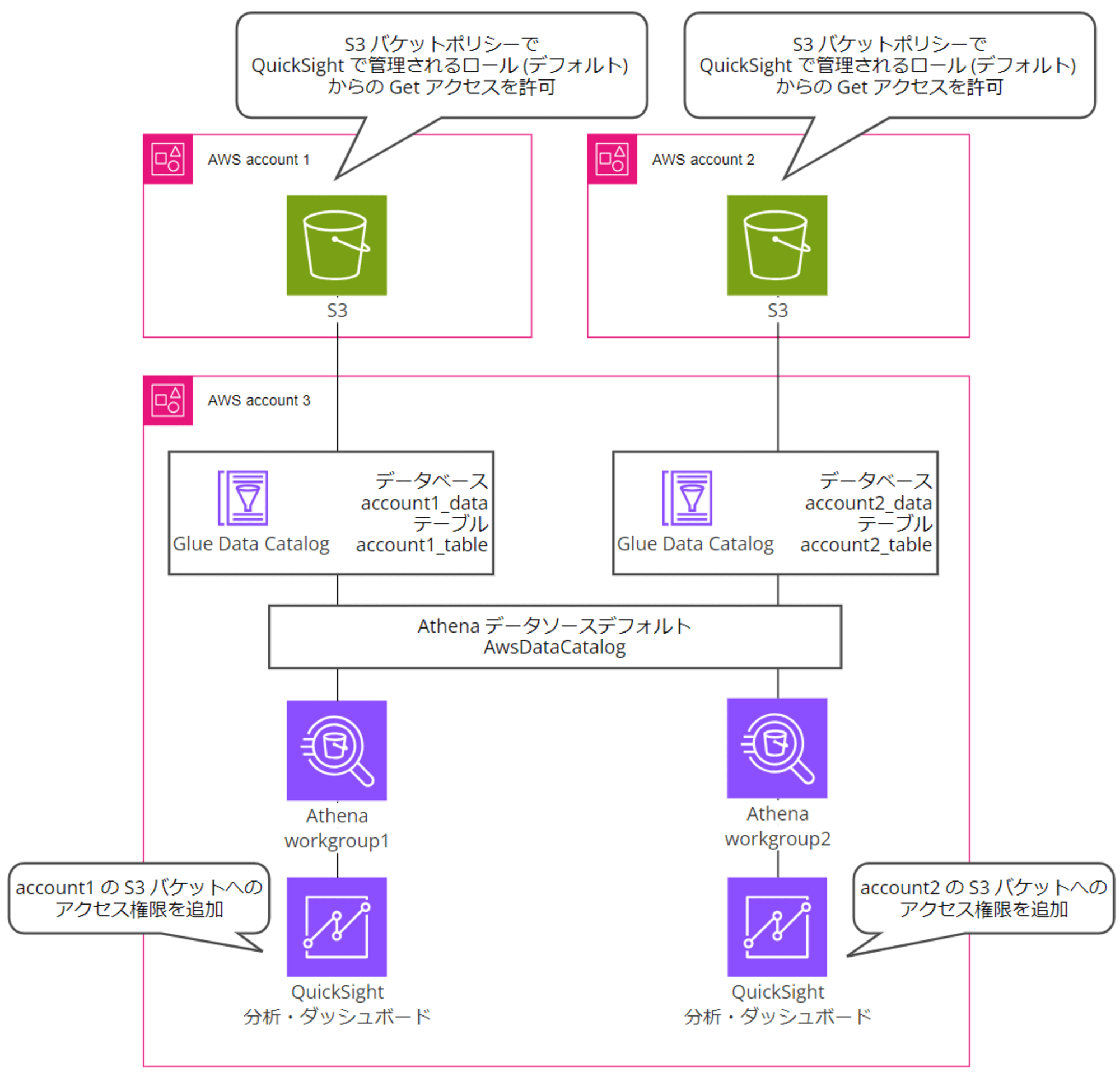
- AWS account 1:ワークロードアカウント 1
- 可視化するデータ元の CSV ファイルを配置する S3 バケットを作成(開発環境のイメージ)
- AWS アカウント ID:111111111111
- AWS account 2:ワークロードアカウント 2
- 可視化するデータ元の CSV ファイルを配置する S3 バケットを作成(本番環境のイメージ)
- AWS アカウント ID:222222222222
- AWS account 3:QuickSight、Athena 用データ分析アカウント
- QuickSight アカウントを有効化し、account 1 とaccount 2 のデータを可視化する
- AWS アカウント ID:333333333333
- その他前提
- QuickSight アカウントはエンタープライズプランで有効化済
- 将来的に多数の匿名ユーザー向けにダッシュボードを公開する予定があり、認証方法は「IAM フェデレーティッド ID と QuickSight で管理されたユーザーを使用する」を選択して有効化
- 東京リージョン
- ピクセルパーフェクトレポートはオフ
- Athena データソースはデフォルトの AwsDataCatalog を併用
- Glue Data Catalog のデータベースとテーブルは AWS アカウントごとに分割する
- 各 AWS アカウントの S3 バケットは SSE-S3 でデフォルト暗号化されている
- QuickSight アカウントはエンタープライズプランで有効化済
ちなみに以降の図解では省きますが、今回の検証環境は複数の AWS アカウントが Control Tower の管理配下にあり、ユーザーを IAM Identity Center 管理しています。
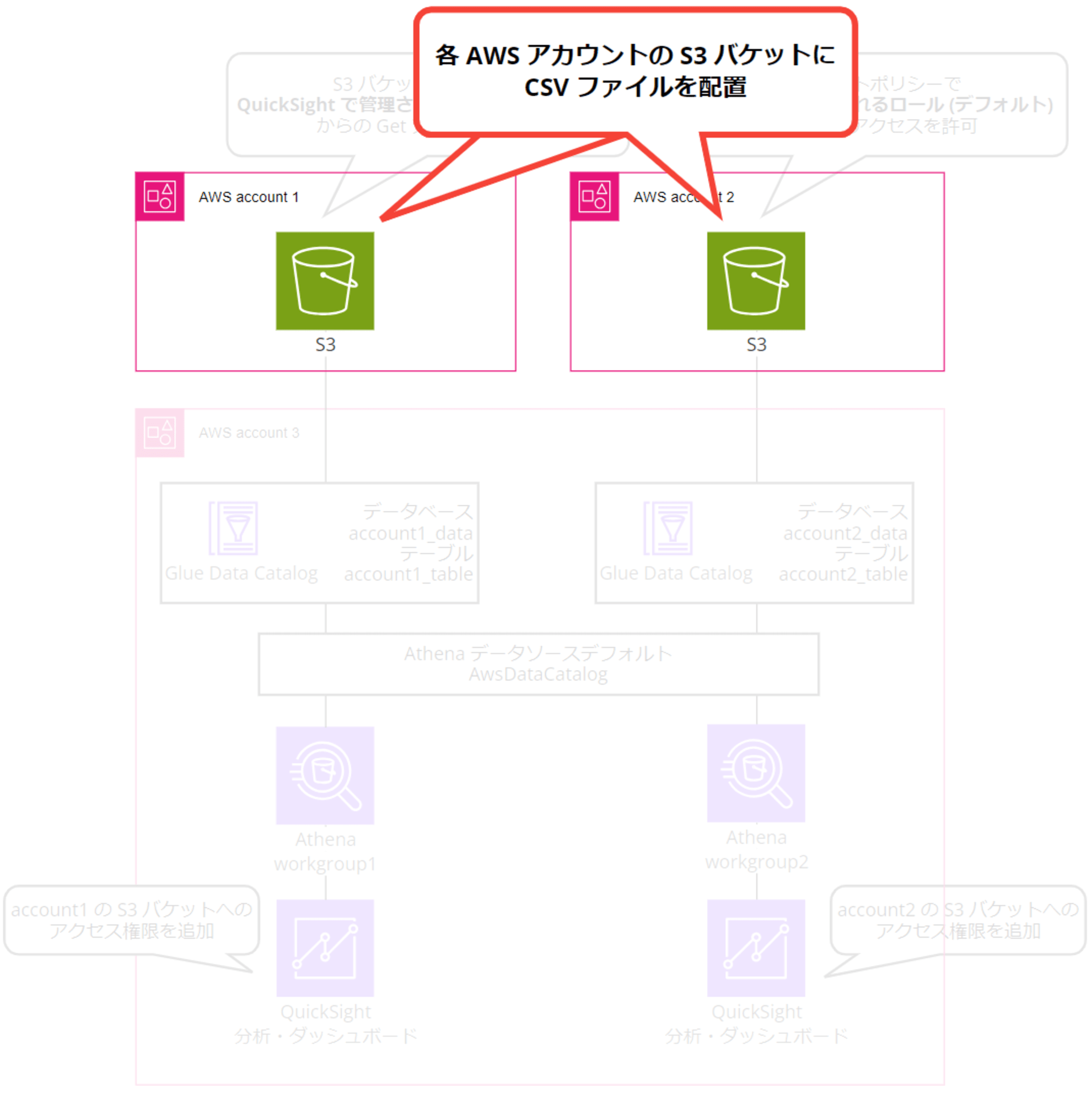
0. テスト用 CSV を S3 バケットに配置
あらかじめ account 1 と account 2 の各 AWS アカウントに S3 バケットを作成し、にテスト用 CSV ファイルを配置しておきます。S3 バケットは名前だけを設定し、他はデフォルト設定で検証していきます。
サッと生成 AI に問い合わせて適当な売り上げデータ CSV を作成したのですが、日によって売っている製品が変わったりしてちょっとおかしいです……テストデータということでご勘弁ください。
開発環境用と本番環境用をイメージして、CSV ファイル名は同じにしています。
- account 1 用に account 1 で作成
- S3 バケット名
- account1-athena-test-111111111111
- 配置パス
s3://account1-athena-test-111111111111/account1/data/sales/year=2024/month=01/sales_data_2024_01.csv
- S3 バケット名
date,product,quantity,unit_price,total_sales
2024-01-01,Widget A,100,25.99,2599.00
2024-01-02,Gadget B,50,49.99,2499.50
2024-01-03,Widget A,75,25.99,1949.25
2024-01-04,Tool C,30,99.99,2999.70
2024-01-05,Gadget B,60,49.99,2999.40
2024-01-06,Tool C,25,99.99,2499.75
2024-01-07,Widget A,120,25.99,3118.80
- account 2 用に account 2 で作成
- S3 バケット名
- account2-athena-test-222222222222
- 配置パス
s3://account2-athena-test-222222222222/account2/data/sales/year=2024/month=01/sales_data_2024_01.csv
- S3 バケット名
date,product,quantity,unit_price,total_sales
2024-01-01,Widget X,80,29.99,2399.20
2024-01-02,Gadget Y,40,59.99,2399.60
2024-01-03,Widget X,65,29.99,1949.35
2024-01-04,Tool Z,35,89.99,3149.65
2024-01-05,Gadget Y,55,59.99,3299.45
2024-01-06,Tool Z,20,89.99,1799.80
2024-01-07,Widget X,110,29.99,3298.90
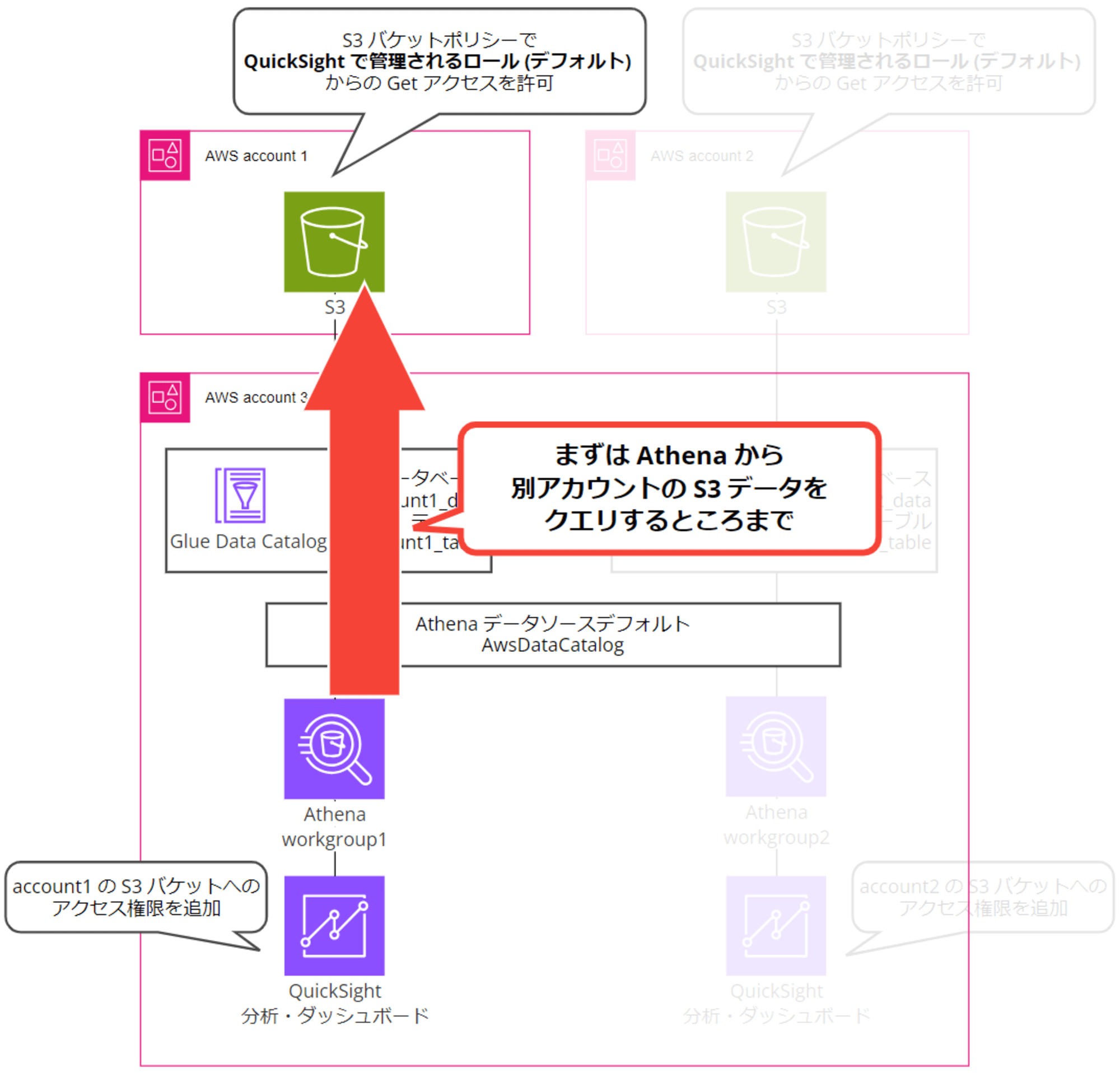
1. Athena から別アカウントの S3 データをクエリする
まずは account 3 の Athena コンソールから account 1 の S3 バケットデータをクエリするところまでを目指します。
1-1. QuickSight、Athena 用データ分析アカウントで許可するサービス ARN を確認
IAM Identity Center ユーザーの AWSAdministratorAccess 権限で account 3(QuickSight、Athena 用データ分析アカウント)にログインします。account 1(ワークロードアカウント 1)の S3 バケットポリシーで許可する ARN を確認するためです。
IAM コンソールで IAM ロール一覧から「SSO」と検索すると、デフォルトで提供されている許可セットで使われる IAM ロールが出てきます。今回は AWSPowerUserAccess と AWSAdministratorAccess からのアクセスを許可したいと思います。
AWSPowerUserAccess と AWSAdministratorAccess ロールの ARN をコピーしておきます。
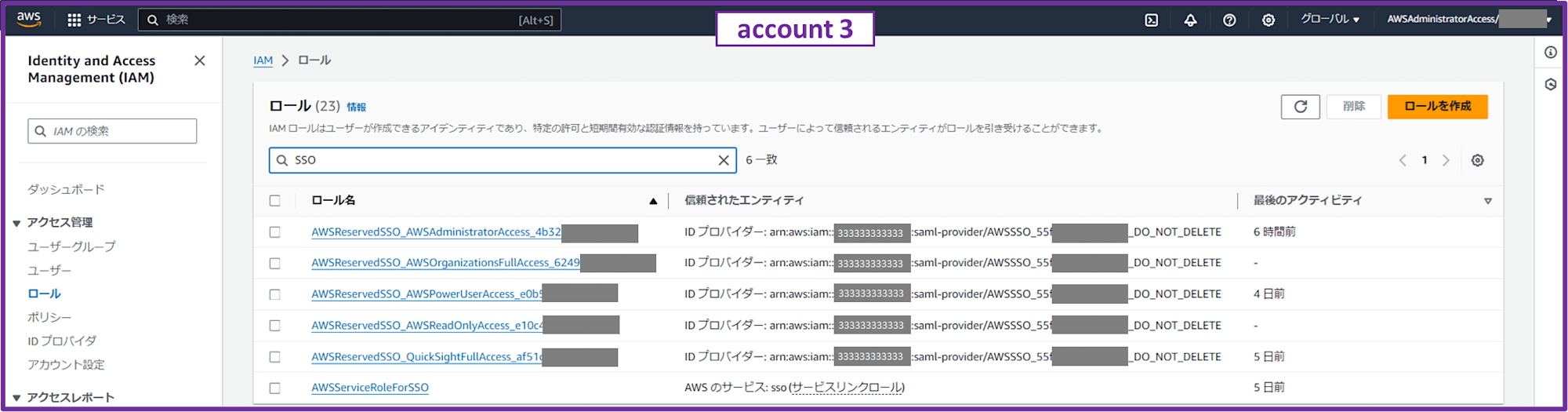
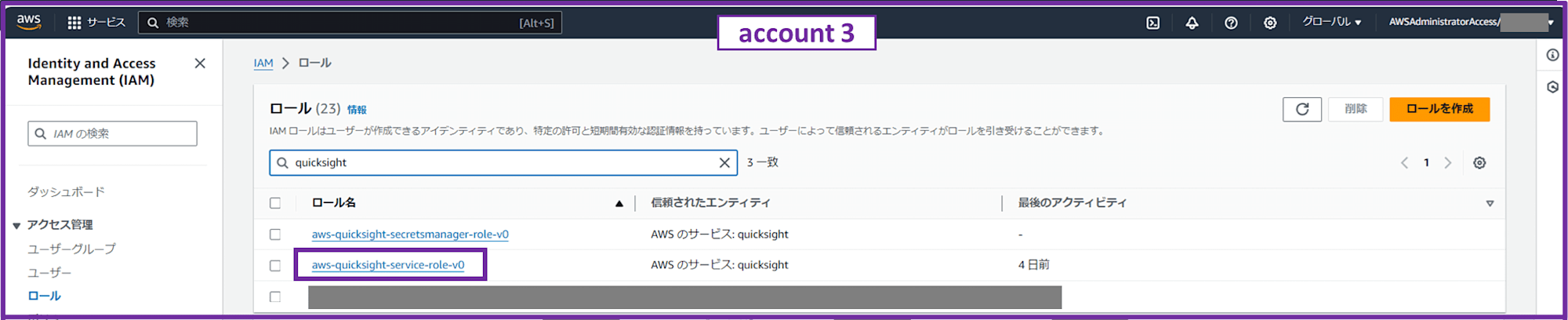
次に「quicksight」と検索して aws-quicksight-service-role-v0 の ARN をコピーします。
これは QuickSight に付与されているデフォルト IAM ロールで、後ほど QuickSight から Athena 経由で可視化する際に必要になるので今のうちに設定しておきます。
1-2. ワークロードアカウントにログインし S3 バケットポリシーを設定
続いて IAM Identity Center ユーザーの AWSAdministratorAccess 権限で account 1(ワークロードアカウント 1)にログインし、S3 バケット「account1-athena-test-111111111111」のバケットポリシーを設定します。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Account1 Bucket Policy",
"Effect": "Allow",
"Principal": {
"AWS": [
"arn:aws:iam::333333333333:role/aws-reserved/sso.amazonaws.com/ap-northeast-1/AWSReservedSSO_AWSPowerUserAccess_e0b5xxxxxxxxxxxx",
"arn:aws:iam::333333333333:role/aws-reserved/sso.amazonaws.com/ap-northeast-1/AWSReservedSSO_AWSAdministratorAccess_4b32xxxxxxxxxxxx",
"arn:aws:iam::333333333333:role/service-role/aws-quicksight-service-role-v0"
]
},
"Action": [
"s3:GetBucketLocation",
"s3:GetObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::account1-athena-test-111111111111",
"arn:aws:s3:::account1-athena-test-111111111111/*"
]
}
]
}
"Principal": { "AWS": [ の中に、account 3 でコピーしておいた ARN を貼り付けてください。
account 2(ワークロードアカウント 2)でも同様に S3 バケットポリシーを設定します。
1-3. QuickSight、Athena 用データ分析アカウントで Athena から S3 バケットに対してクエリ
IAM Identity Center ユーザーの AWSAdministratorAccess 権限で account 3(QuickSight、Athena 用データ分析アカウント)にログインします。
ここで account 1 の S3 バケットポリシーに許可設定した AWSPowerUserAccess または AWSAdministratorAccess 以外の権限でログインすると、 S3 バケットのデータへの Athena クエリでアクセスが拒否されて失敗します。
1-3-1. Athena クエリ結果保存用 S3 バケットを作成
Athena クエリ結果保存用の S3 バケットを作成します。SSE-S3 でデフォルト暗号化しておきます。
- account1 用
- S3 バケット名
- account1-athena-results-333333333333
- S3 バケット名
- account2 用
- S3 バケット名
- account2-athena-results-333333333333
- S3 バケット名
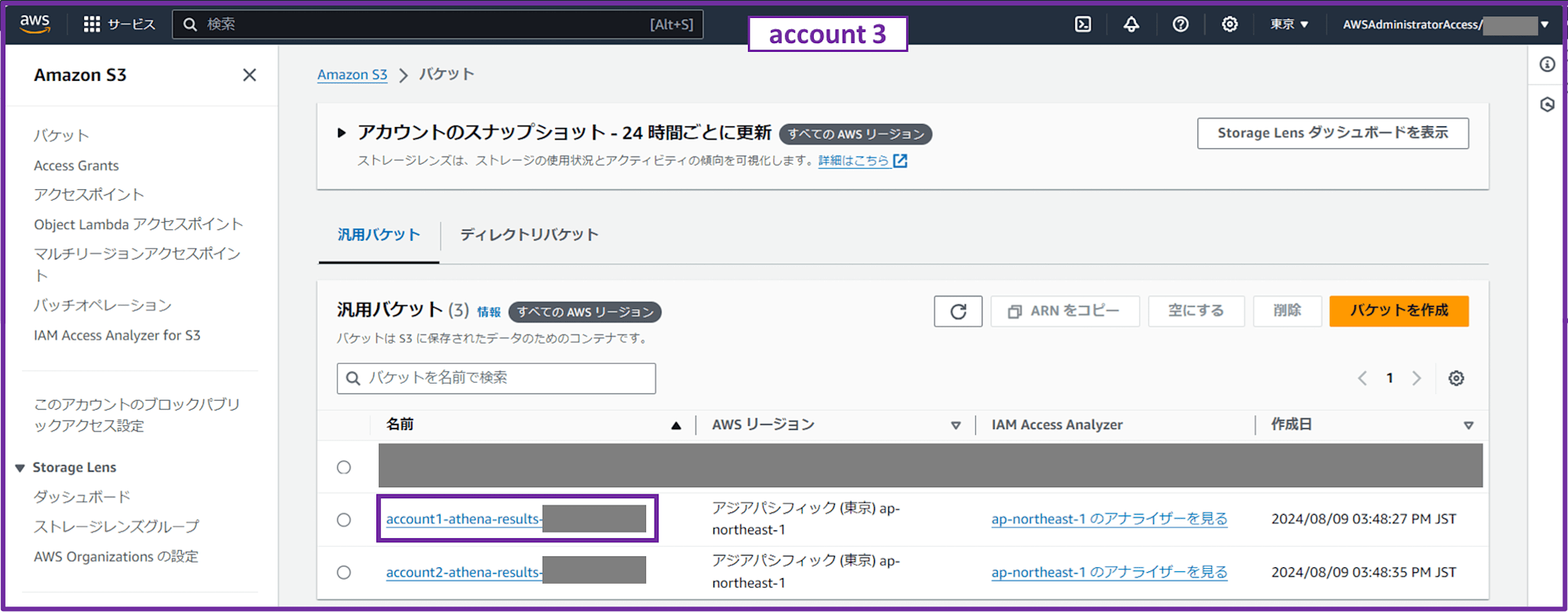
各ワークロードアカウントごとで別々にバケットを作成しましたが、特にこのバケットの中身を直接見るようなケースが思い浮かばないので、同じバケット内でプレフィックスを分けるくらいでもいいかもしれません。
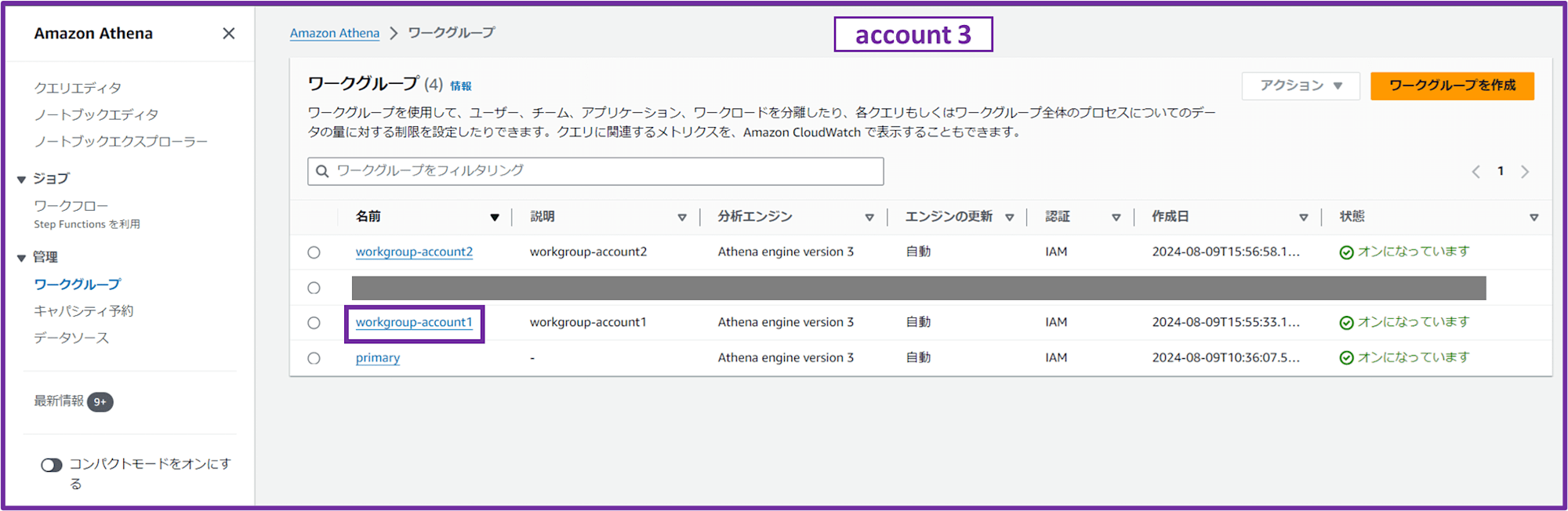
1-3-2. Athena ワークグループを作成
Athena コンソールでワークグループを作成します。
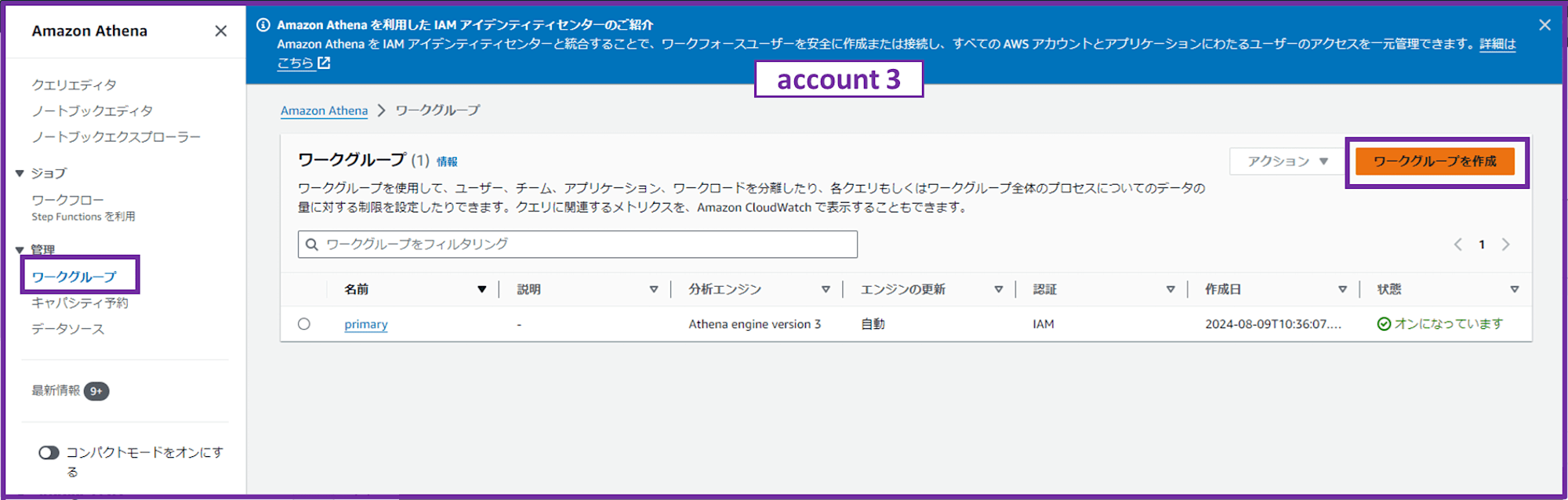
- ワークグループ名:workgroup-account1
- 説明;workgroup-account1
- エンジンのタイプを選択:Athena SQL
- クエリエンジンをアップグレード:自動
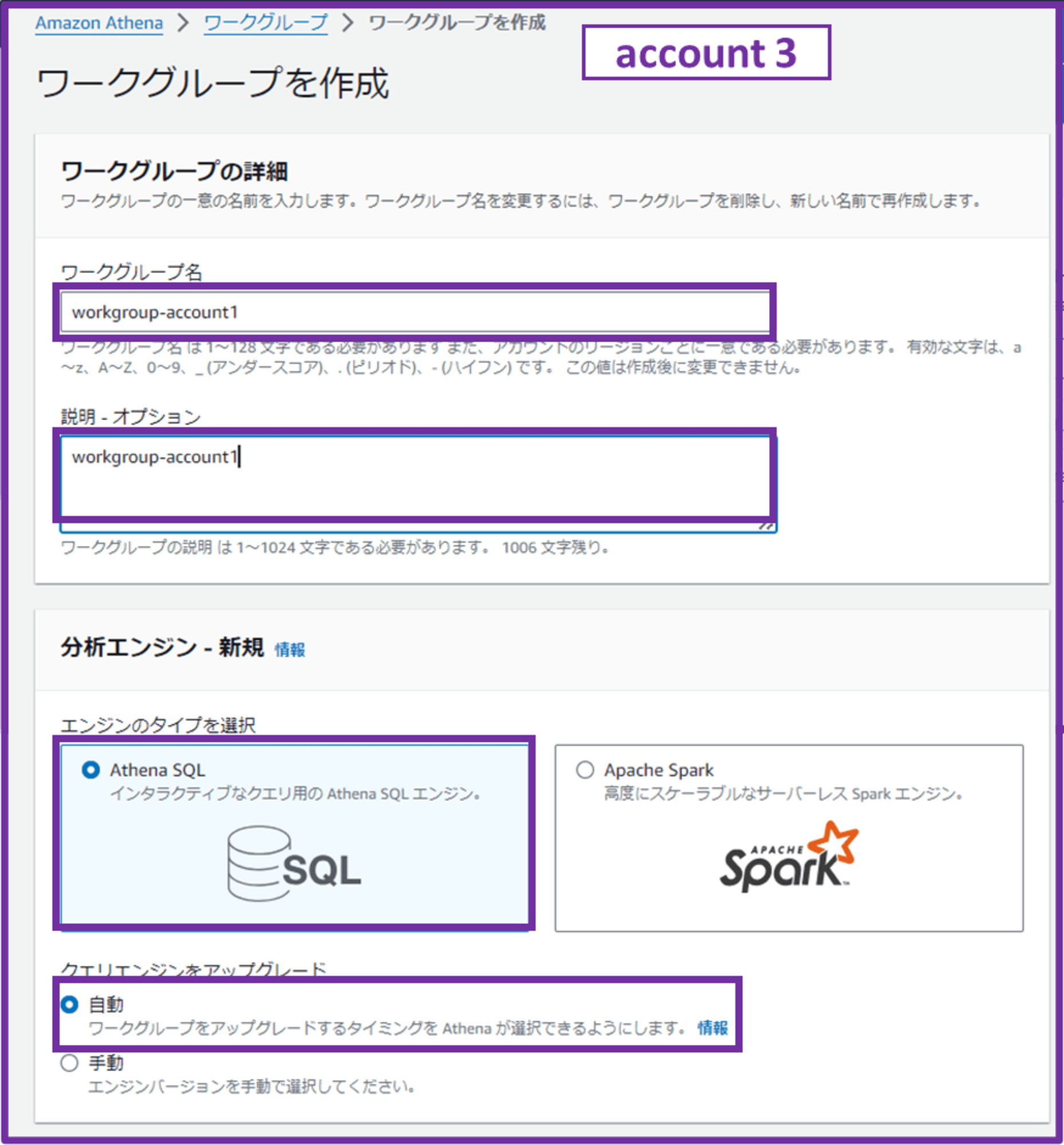
- 認証:AWS Identity and Access Management (IAM)
IAM Identity Center が有効になっているので IAM Identity Center を使った方が良いかな?とも思ったのですが、QuickSight のユーザー管理でも IdC は使わないので、今回はこのまま IAM ですすめます。
IAM Identity Center を使うケースは、EMR Studio を使っていたり、S3 Access Grants や Lake Formation を導入する予定がある場合に有用っぽいです。こちらもいつか試してみようと思います。
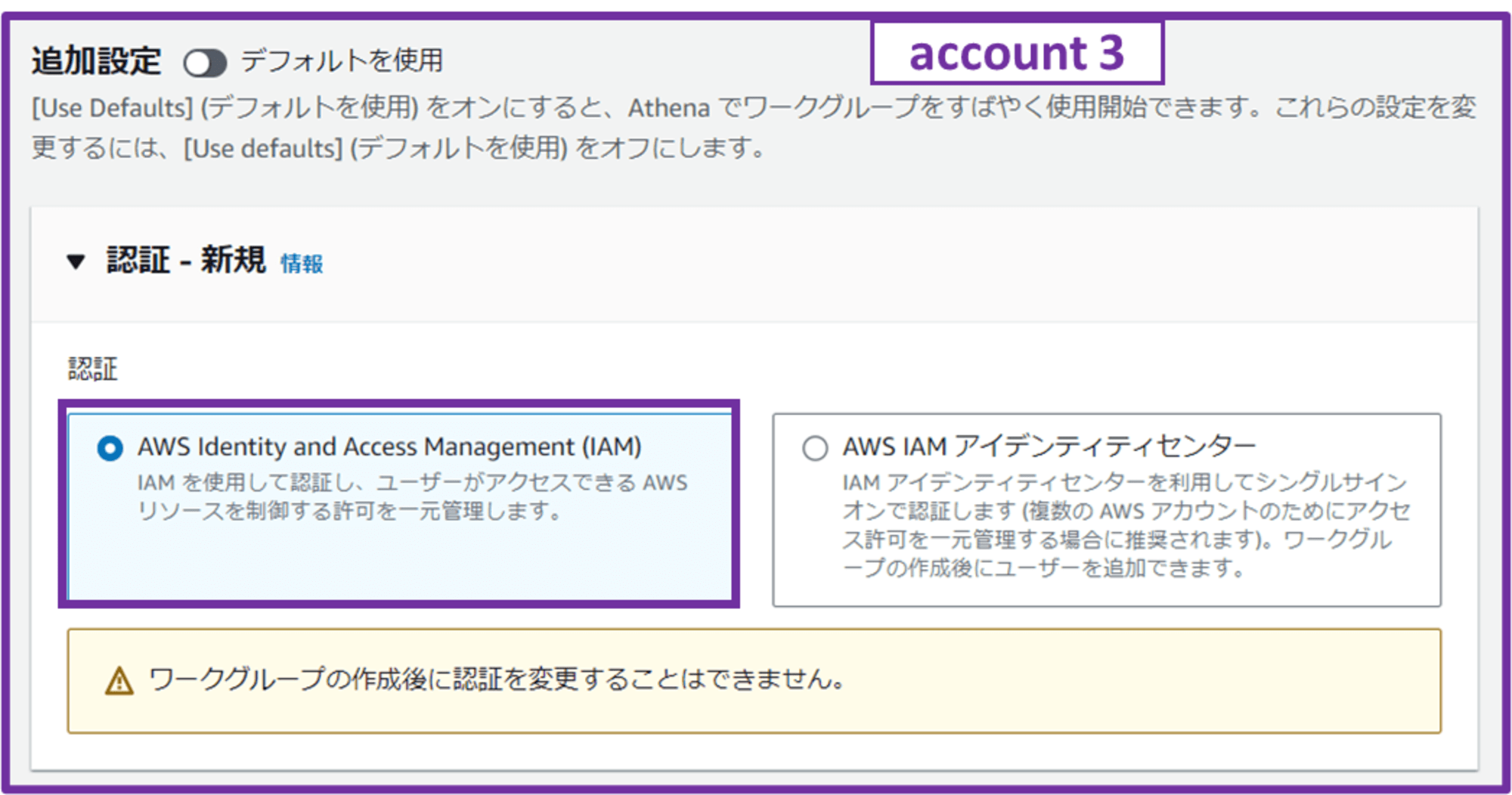
- クエリ結果の場所
- 「1-3-1. Athena クエリ結果保存用 S3 バケットを作成」で作成した S3 バケットを選択
- 予期されるバケット所有者
- 未入力
- クエリ結果をこのアカウント内(account 3)に保存するため
- 未入力
- バケット所有者にクエリ結果に対する完全なコントロールを割り当てる
- チェックしない
- クエリ結果をこのアカウント内(account 3)に保存するため
- チェックしない
- クエリ結果を暗号化
- チェックする
- 暗号化タイプ
- SSE_S3
- 最小暗号化
- チェックしない
- S3 バケット側で SSE-S3 デフォルト暗号化しているので、チェックはしなくても良いかなと考えました。
- チェックしない
- AWS CloudWatch にクエリメトリクスを発行
- チェックする(デフォルト)
- データ制限
- 10 TB(任意のデータ量を設定)
クエリがスキャンするデータの上限を設定します。
「Athena 破産」という言葉も聞いたことがあるので、ここで上限を決めておいて必要以上にクエリされそうになったらキャンセルするようにできるのは良いですね。
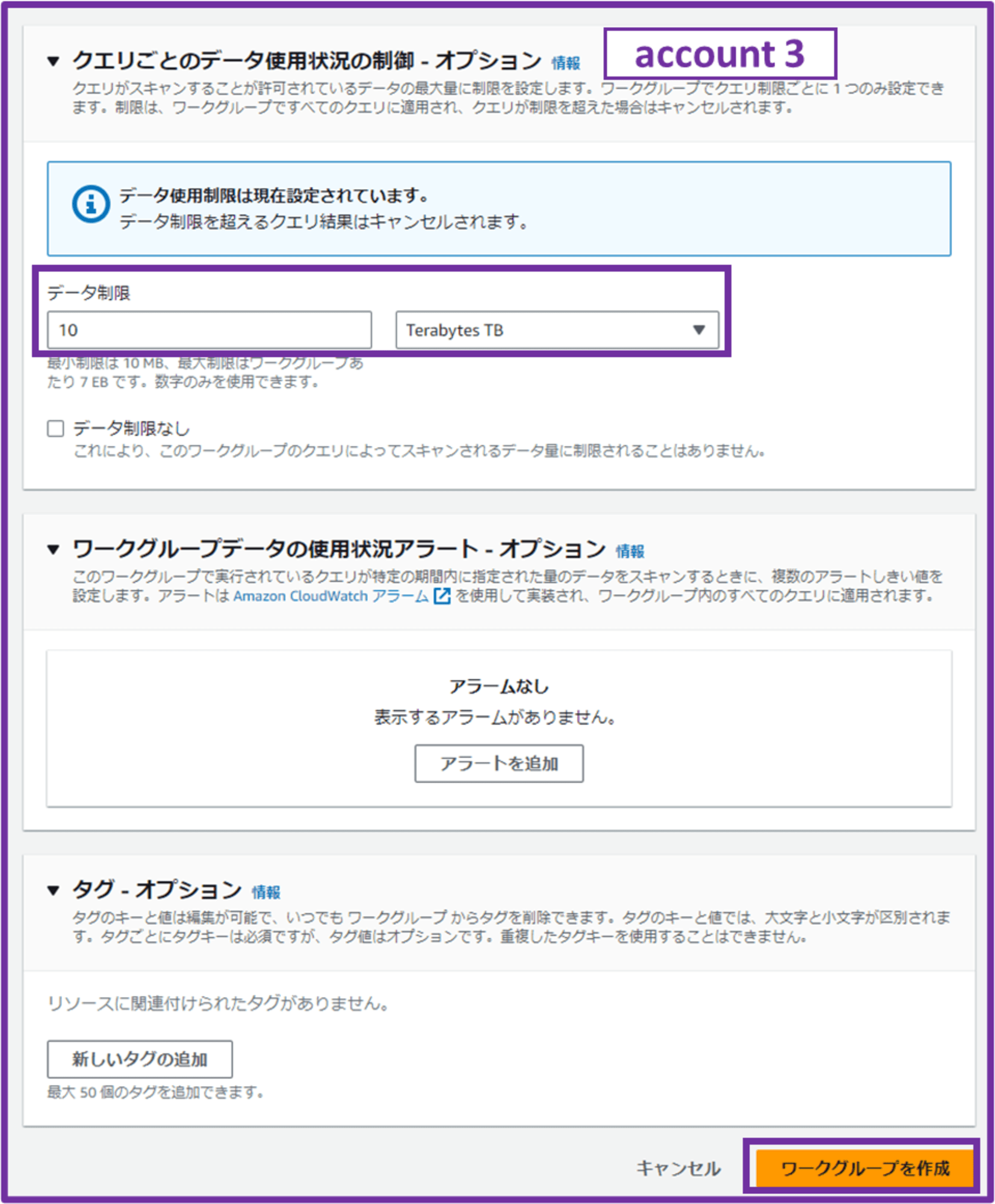
「ワークグループを作成」をクリックして完了です。account 2 用のワークグループも同様に作成しました。
1-3-3. Athena クエリの実行
Athena クエリエディタを開き、画面右上で作成したワークグループ「workgroup-account1」を選択します。
画面左の「データ」部分で、データソースが「AwsDataCatalog」であることを確認します。
クエリエディタに以下のクエリを入力して実行し、データベースを作成します。
CREATE DATABASE IF NOT EXISTS account1_data;
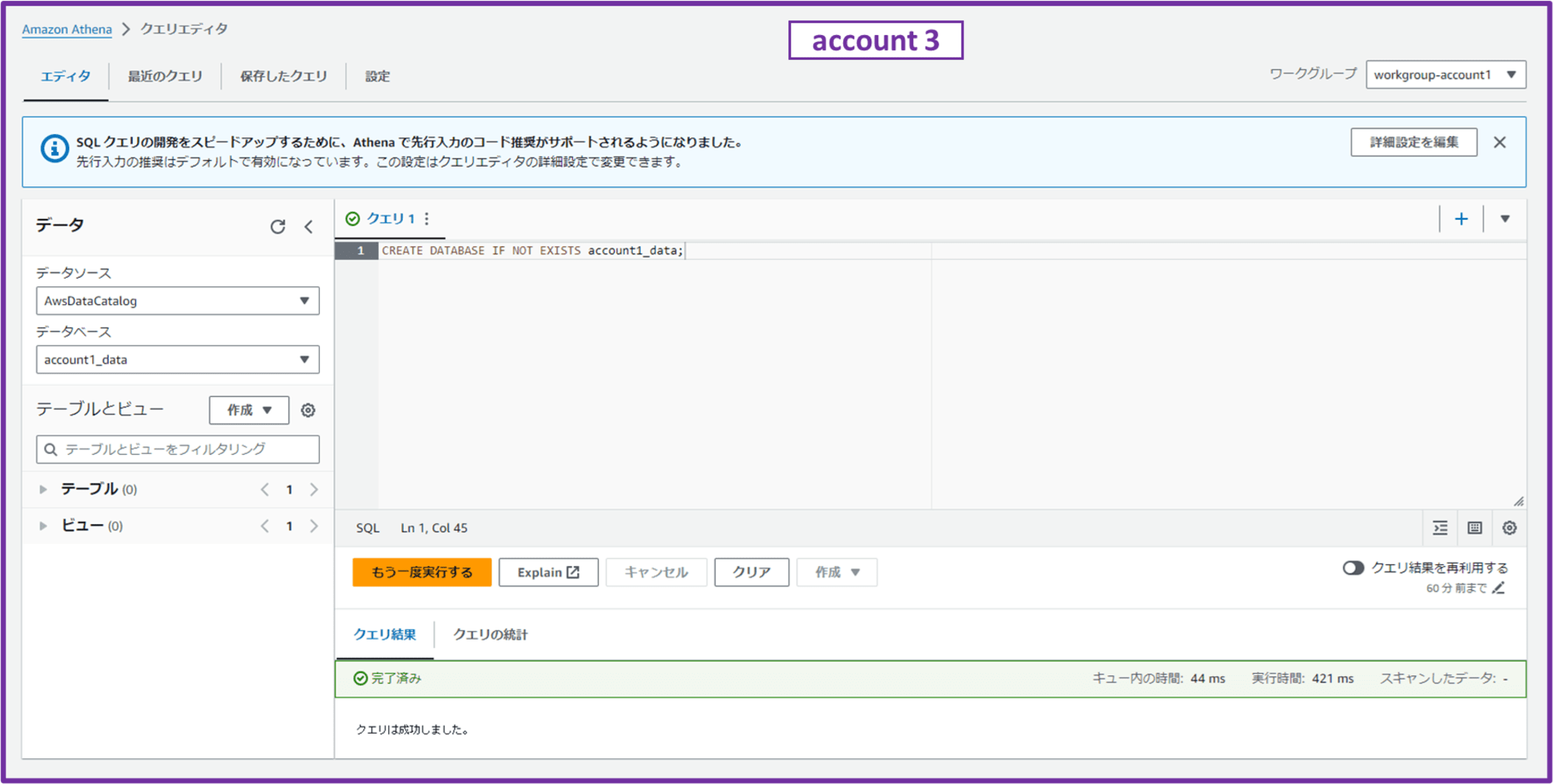
クエリ結果が「完了済み」となり、画面左のデータベースに「account1_data」というデータベースが作成されていれば OK です。
ちなみにここで作成したデータベースは Glue コンソールの「Databases」から確認できます。
続いて作成したデータベース「account1_data」にテーブルを作成します。
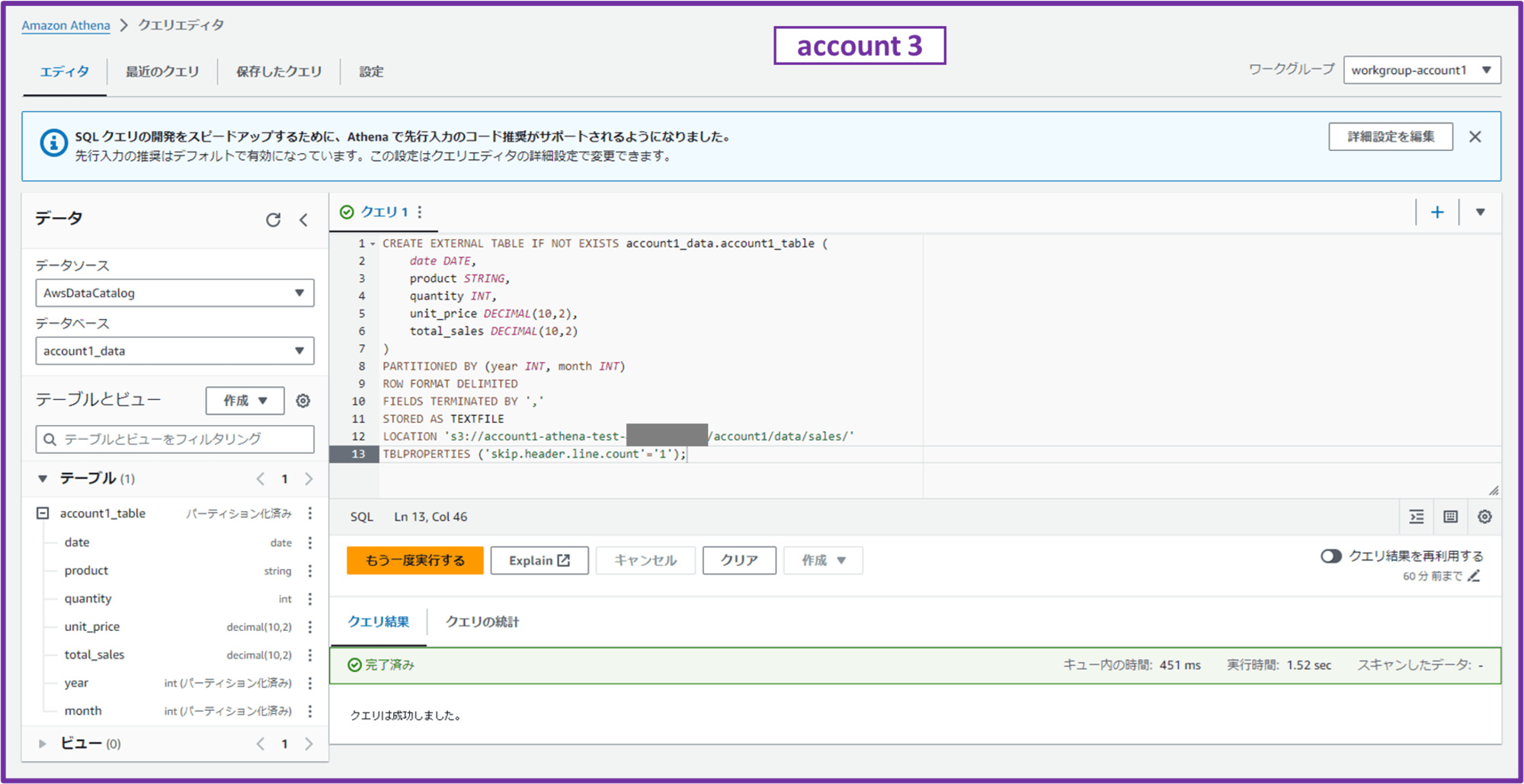
CREATE EXTERNAL TABLE IF NOT EXISTS account1_data.account1_table (
date DATE,
product STRING,
quantity INT,
unit_price DECIMAL(10,2),
total_sales DECIMAL(10,2)
)
PARTITIONED BY (year INT, month INT)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION 's3://account1-athena-test-111111111111/account1/data/sales/'
TBLPROPERTIES ('skip.header.line.count'='1');
クエリの内容
- 「0. テスト用 CSV を S3 バケットに配置」で配置した CSV ファイルの中身から、CSV ファイルの各列(カラム)のデータ型を決定
- date → DATE
- 日付情報を格納
- product → STRING(または VARCHAR)
- 文字列。商品名を格納
- quantity → INT
- 整数値。商品数量を格納
- unit_price → DECIMAL(10,2)(小数点以下2桁の数値)
- 10 桁までの数値で、小数点以下 2 桁までの単価情報を格納
- total_sales → DECIMAL(10,2)(小数点以下2桁の数値)
- 10 桁までの数値で、小数点以下 2 桁までの売上合計額を格納
- date → DATE
CREATE EXTERNAL TABLE IF NOT EXISTS account1_data.account1_table (~)account1_dataというデータベースに、account1_tableというテーブルを作成- CREATE TABLE - Amazon Athena
- テーブルのカラムを定義
IF NOT EXISTSはテーブルが既に存在する場合にはエラーを出さずにスキップするオプション
PARTITIONED BY (year INT, month INT)- テーブルを
year(年)とmonth(月)でパーティション分割する
- テーブルを
ROW FORMAT DELIMITED- データのフォーマットが区切り文字によって区切られていることを指定
FIELDS TERMINATED BY ','- 各フィールドがカンマ(
,)で区切られていることを指定
- 各フィールドがカンマ(
STORED AS TEXTFILE- データがテキストファイル形式で保存されていることを指定
LOCATION 's3://account1-athena-test-111111111111/account1/data/sales/'- パーティションのルートディレクトリを
s3://account1-athena-test-111111111111/account1/data/sales/と指定- 年単位(year)や月単位(month)ごとのパーティションディレクトリをこのパスの下に配置
- パーティションのルートディレクトリを
TBLPROPERTIES ('skip.header.line.count'='1');- ファイルの最初の 1 行はヘッダー行として無視する
- Amazon Athenaがヘッダ行のスキップをサポートしました! | DevelopersIO
クエリ結果が「完了済み」となり、画面左のテーブルに「account1_table」というテーブルが作成されていれば OK です。
ここで作成したテーブルは Glue コンソールの「Tables」から確認できます。
クエリの中で LOCATION を指定していますが、この LOCATION では直接 CSV ファイルを指定せず、パーティションデータを格納するルートディレクトリを指定しています。
パーティションとは、大量のデータを効率的に管理するために特定の基準(年単位や月単位など)でデータを分割する方法です。売上データを年ごと、月ごとに分割して保存すると、特定の月だけを素早くクエリすることができ、クエリのパフォーマンスが向上します。
今回はテーブル作成クエリを実行してパーティションデータを格納するルートディレクトリ('s3://account1-athena-test-111111111111/account1/data/sales/')にテーブルを作成しました。実際にはこのルートディレクトリの下に、データがパーティション(年、月で分けられたデータ)ごとに保存されます。
Athena は自動的に S3 に保存されているパーティションを認識しないので、テーブルを作成した後で S3 にあるパーティション(今回は year=2024/month=01/)の場所を Athena に手動で登録します。
ALTER TABLE account1_data.account1_table ADD
PARTITION (year=2024, month=01)
LOCATION 's3://account1-athena-test-111111111111/account1/data/sales/year=2024/month=01/';
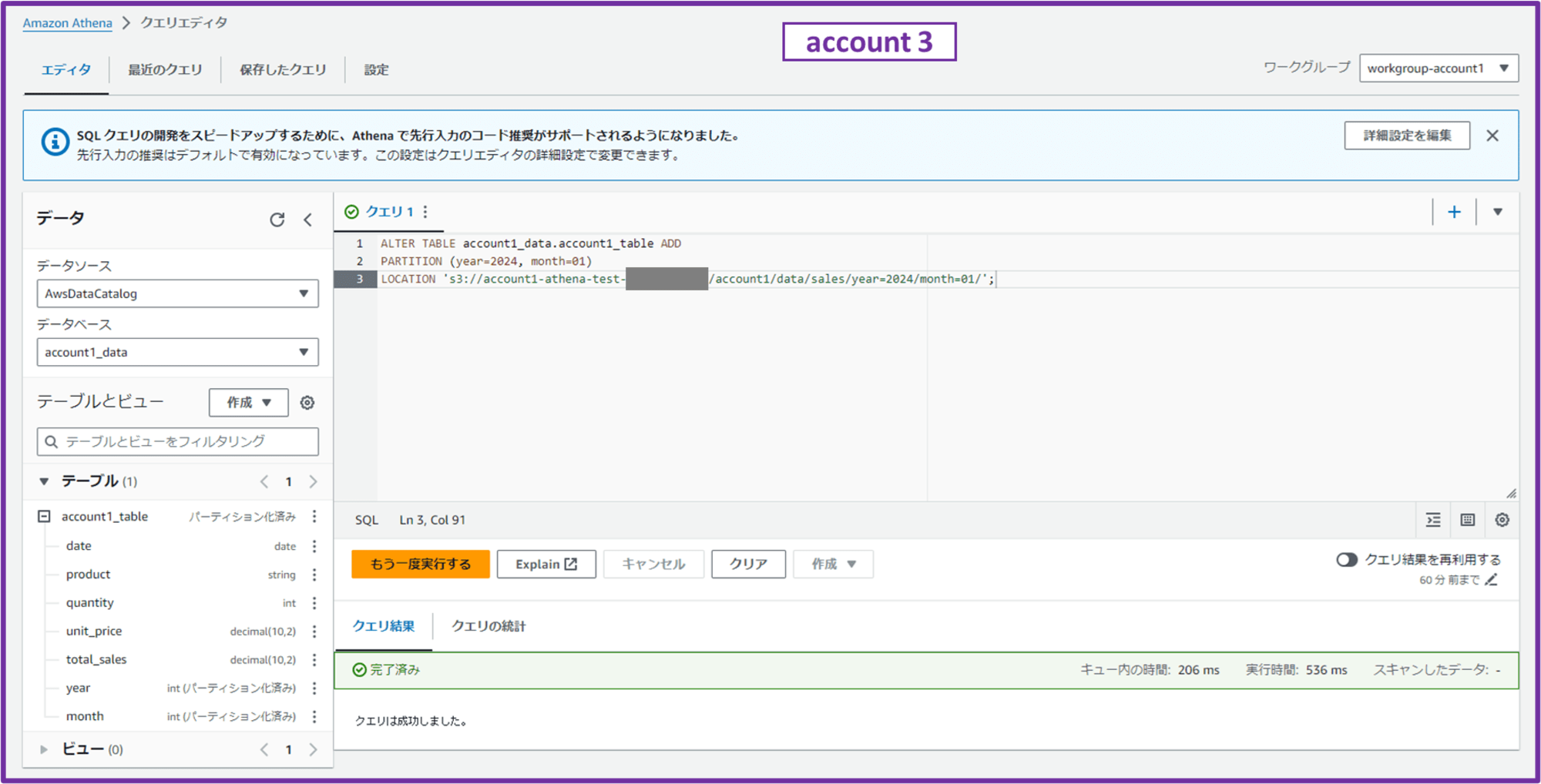
クエリ結果が「完了済み」となれば OK です。
今回は検証なのでこれだけですが、2 月、3 月…と新しい売上データが追加される度に対応するパーティションを追加する必要があります。大量のパーティションがある場合は Glue クローラーを使用して自動的にパーティションを検出・追加することも可能です。Partition Projection という機能も使えるようです。
では、いよいよ別アカウント(account 1)の S3 バケットに Athena からクエリします。
SELECT * FROM account1_data.account1_table
WHERE year = 2024 AND month = 01
LIMIT 10;
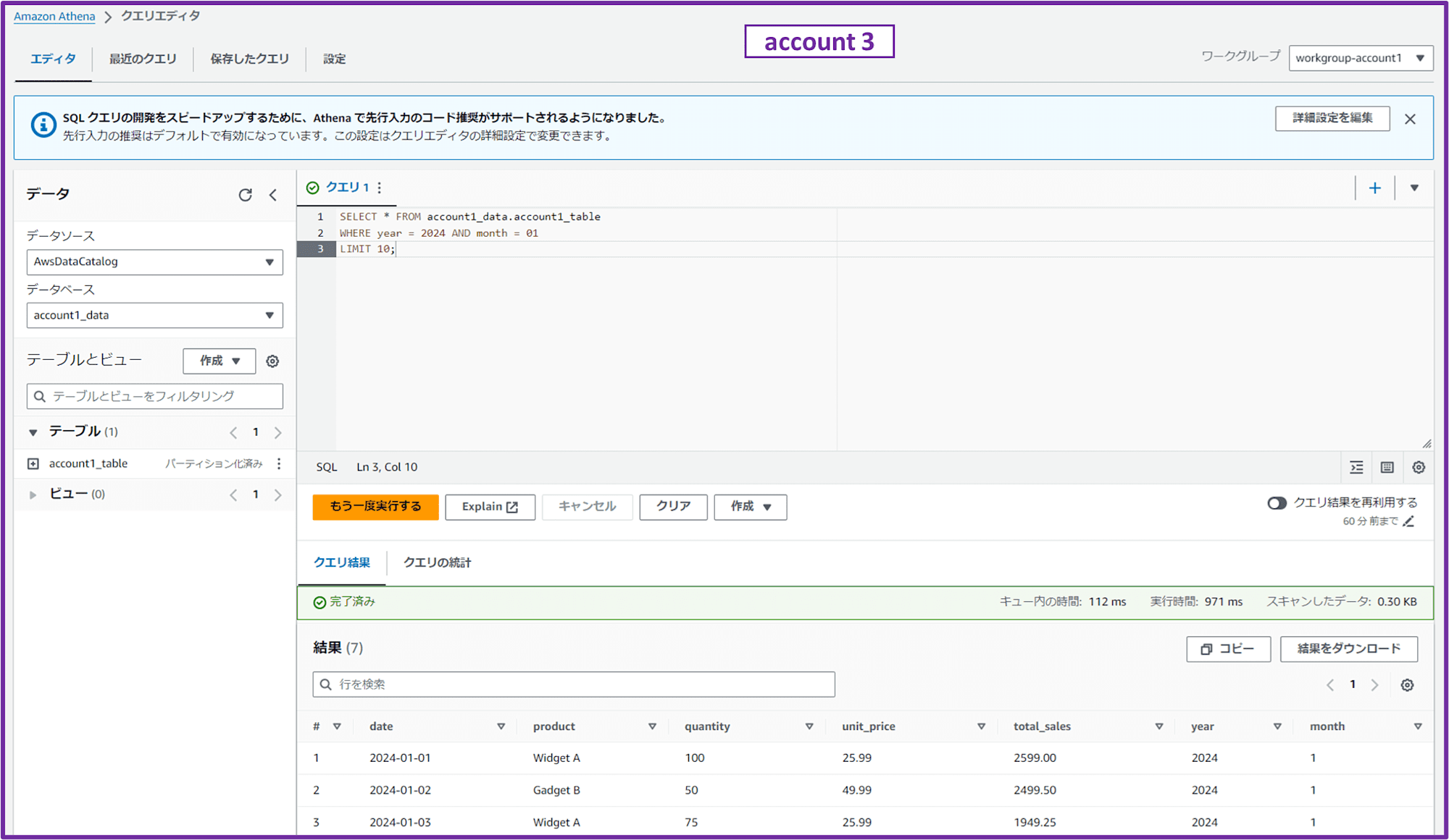
account 1 の S3 バケットに格納した CSV ファイルの中身をクエリできました。
ブログでは省きますが、同様に acount 2 に対しても
- ワークロードアカウント 2 にログインし S3 バケットポリシーを設定
- QuickSight、Athena 用データ分析アカウントで
- Athena ワークグループを作成
- Athena から S3 バケットに対してクエリ
の手順をおこなえば、同じように acount 3 の Athena から account 2 の S3 バケットの内容をクエリできます。
2. QuickSight で Athena を介して別アカウントの S3 データを可視化する
では QuickSight で Athena を介して別アカウントの S3 データを可視化していきます。
ここから QuickSight での操作になりますが、IAM 権限を持つ QuickSight ユーザーで作業をしていきます。
今回は IAM Identity Center ユーザーの AWSAdministratorAccess 権限で account 3 の AWS コンソールにログインし、QuickSight ユーザーをプロビジョニングしています。
2-1. QuickSight の許可設定
QuickSight アカウントに、QuickSight ユーザーでログインしました。
画面右上の人型アイコンから、「QuickSight を管理」をクリックします。
「セキュリティとアクセス許可」メニューを開きます。
「QuickSight の AWS のサービスへのアクセス」で「管理」をクリックします。
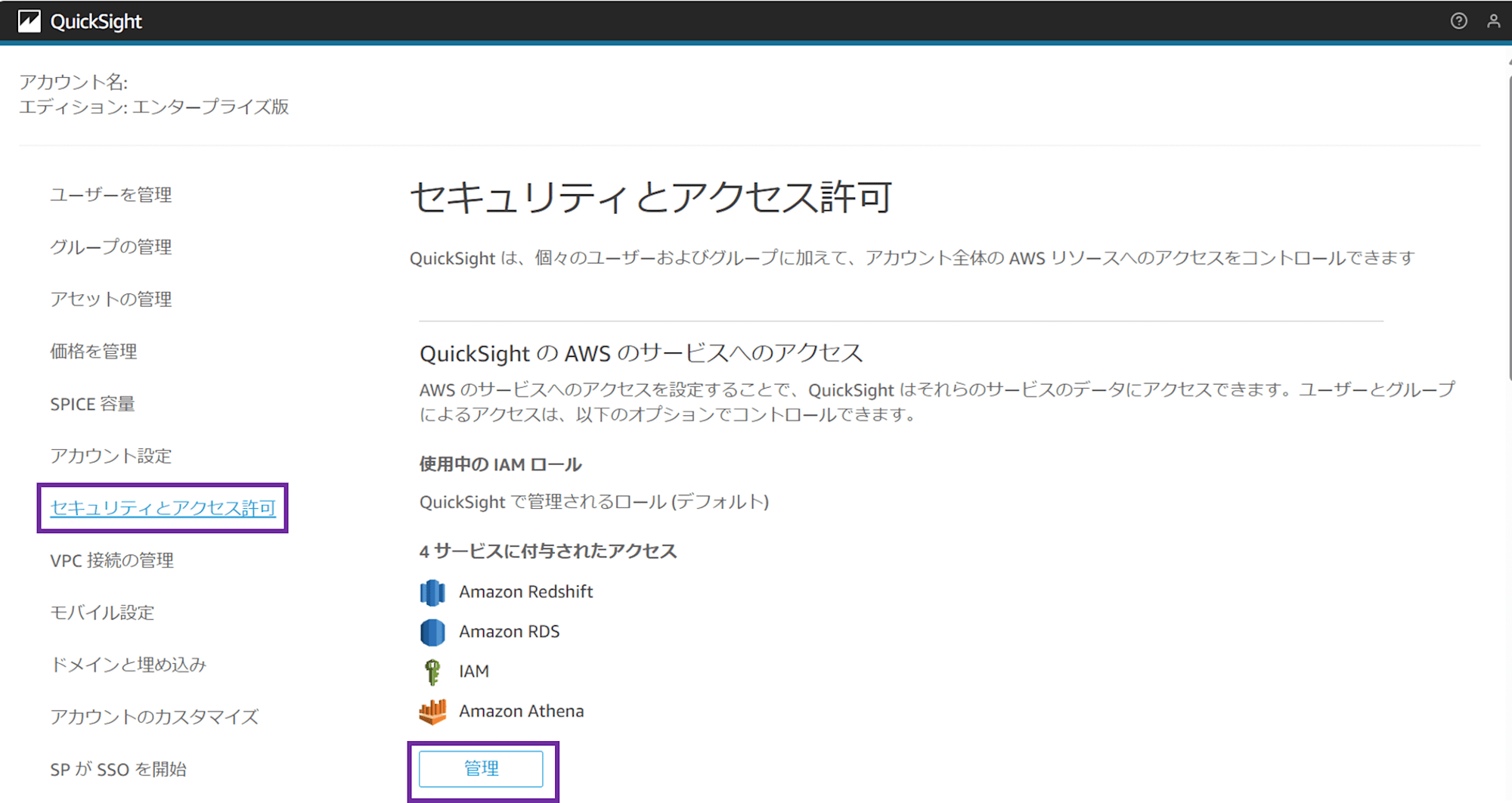
IAM ロールは「QuickSight で管理されるロールを使用する(デフォルト)」を選択したままにしておきます。ここで指定している IAM ロールが、S3 バケットポリシーで許可した aws-quicksight-service-role-v0 です。
Amazon S3 にチェックを入れ、「S3 バケットを選択する」をクリックします。
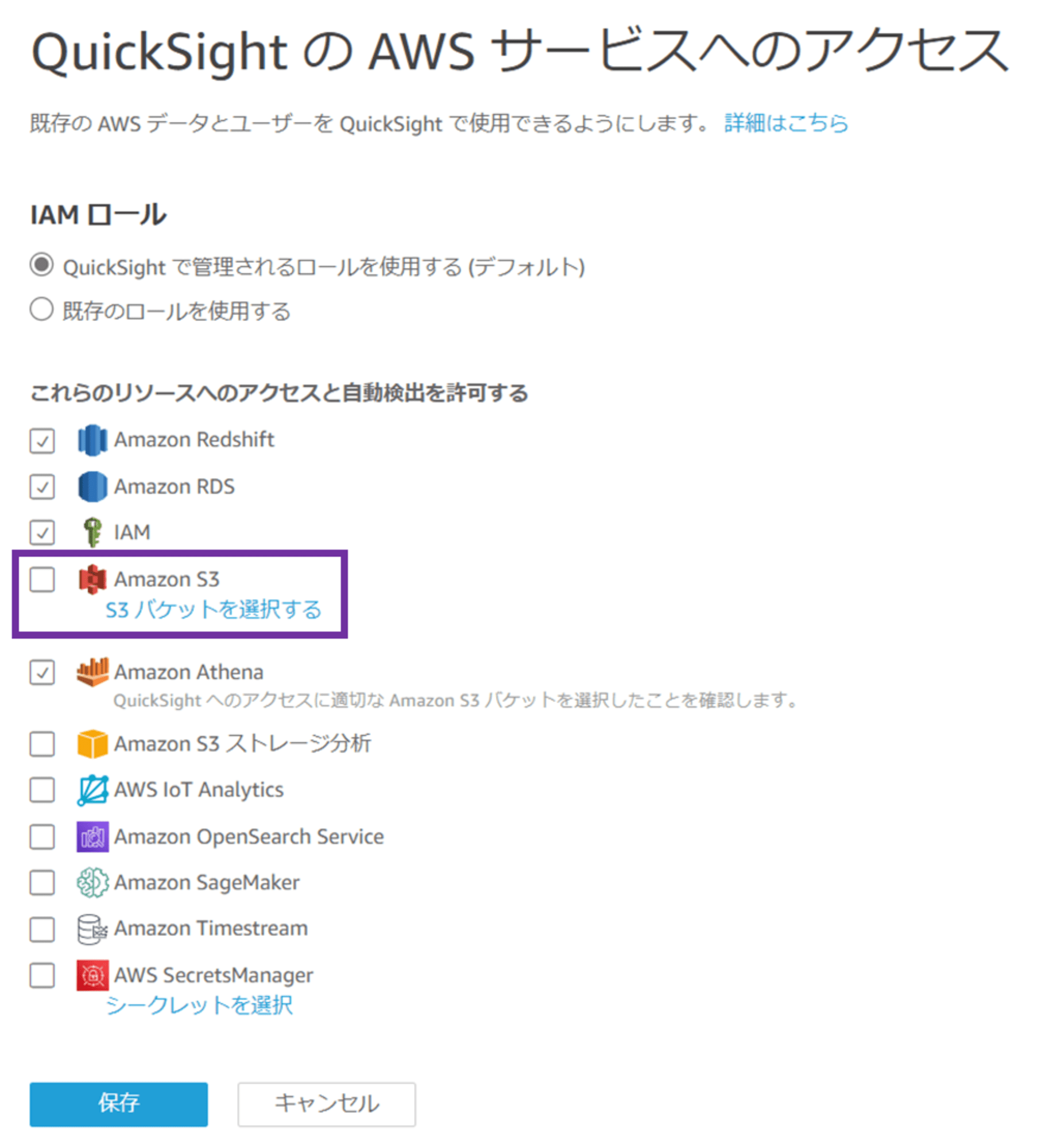
「QuickSight アカウントにリンクされている S3 バケット」が選択されており、account 3 内に存在する S3 バケットの一覧が表示されます。ここで、Athena クエリ結果保存用の S3 バケットにチェックし、「Athena Workgroup の書き込みアクセス許可」にもチェックします。
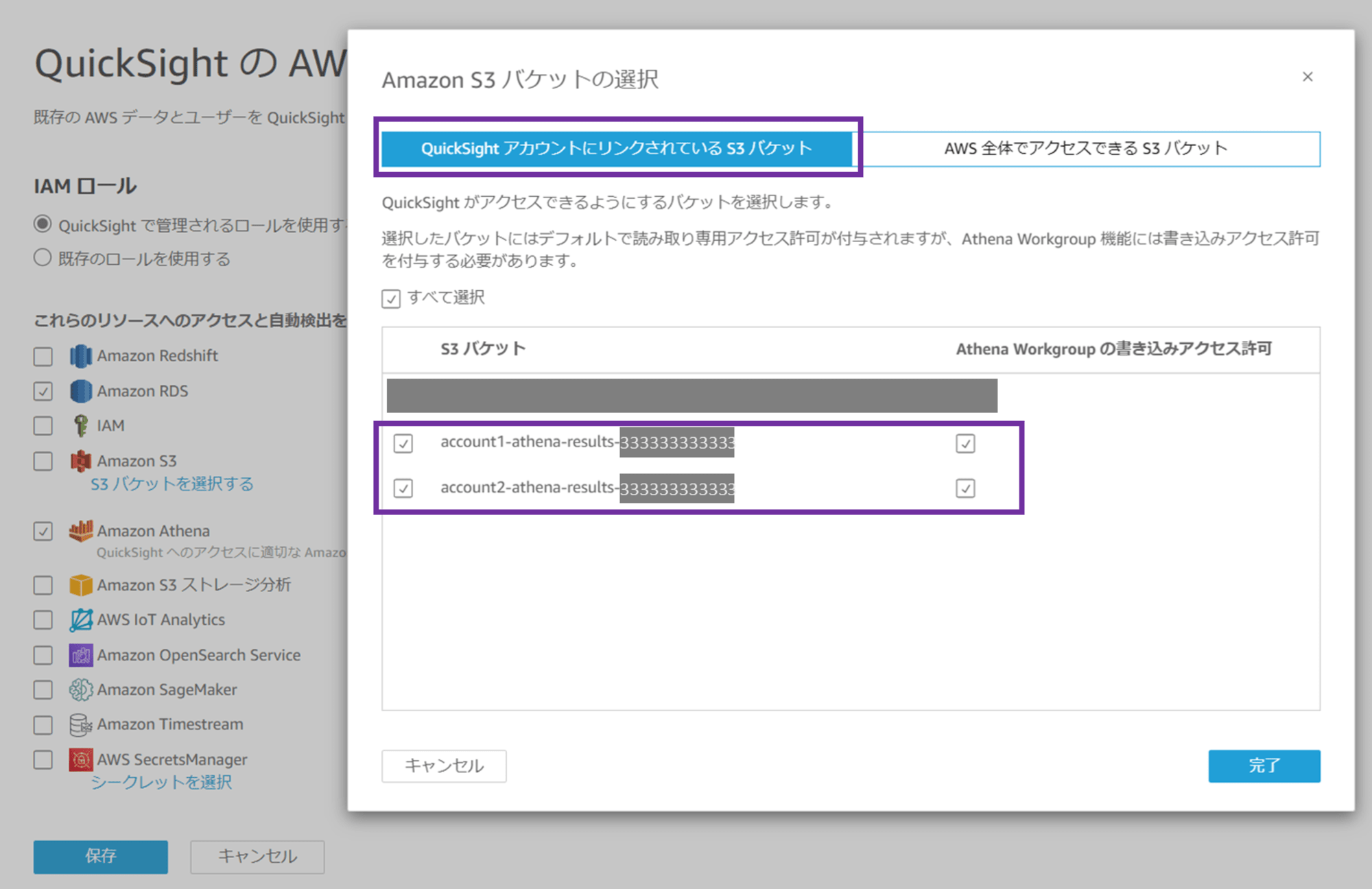
続いて「AWS 全体でアクセスできる S3 バケット」を選択します。「別の S3 バケットを使用」にチェックし、ワークロードアカウント 1(account 1)の S3 バケット名を入力します。元データの CSV ファイルが保存されている、クエリ先 S3 バケットです。
バケット名を入力したら「S3 バケットの追加」をクリックします。
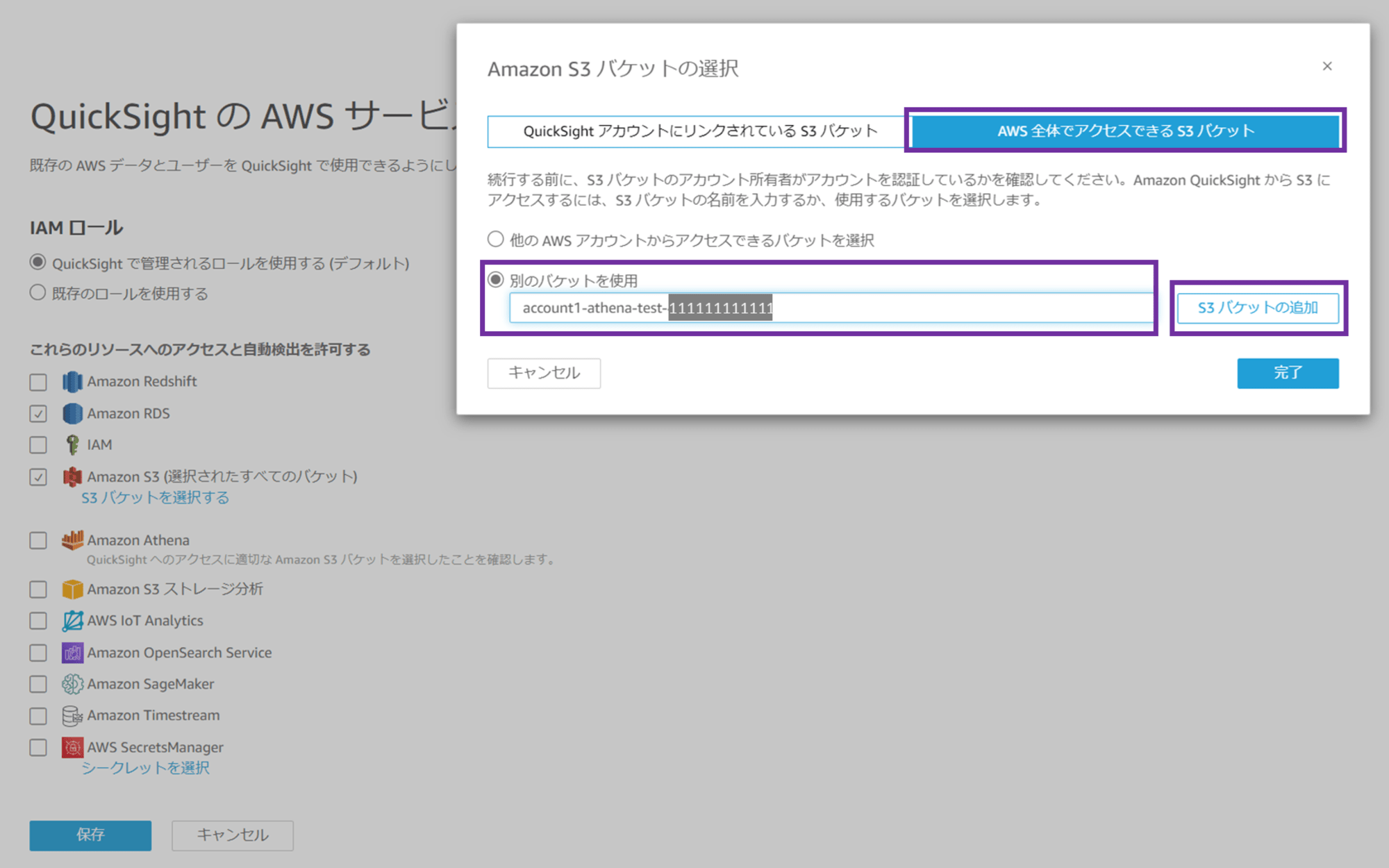
バケット名が追加されました。「完了」をクリックします。
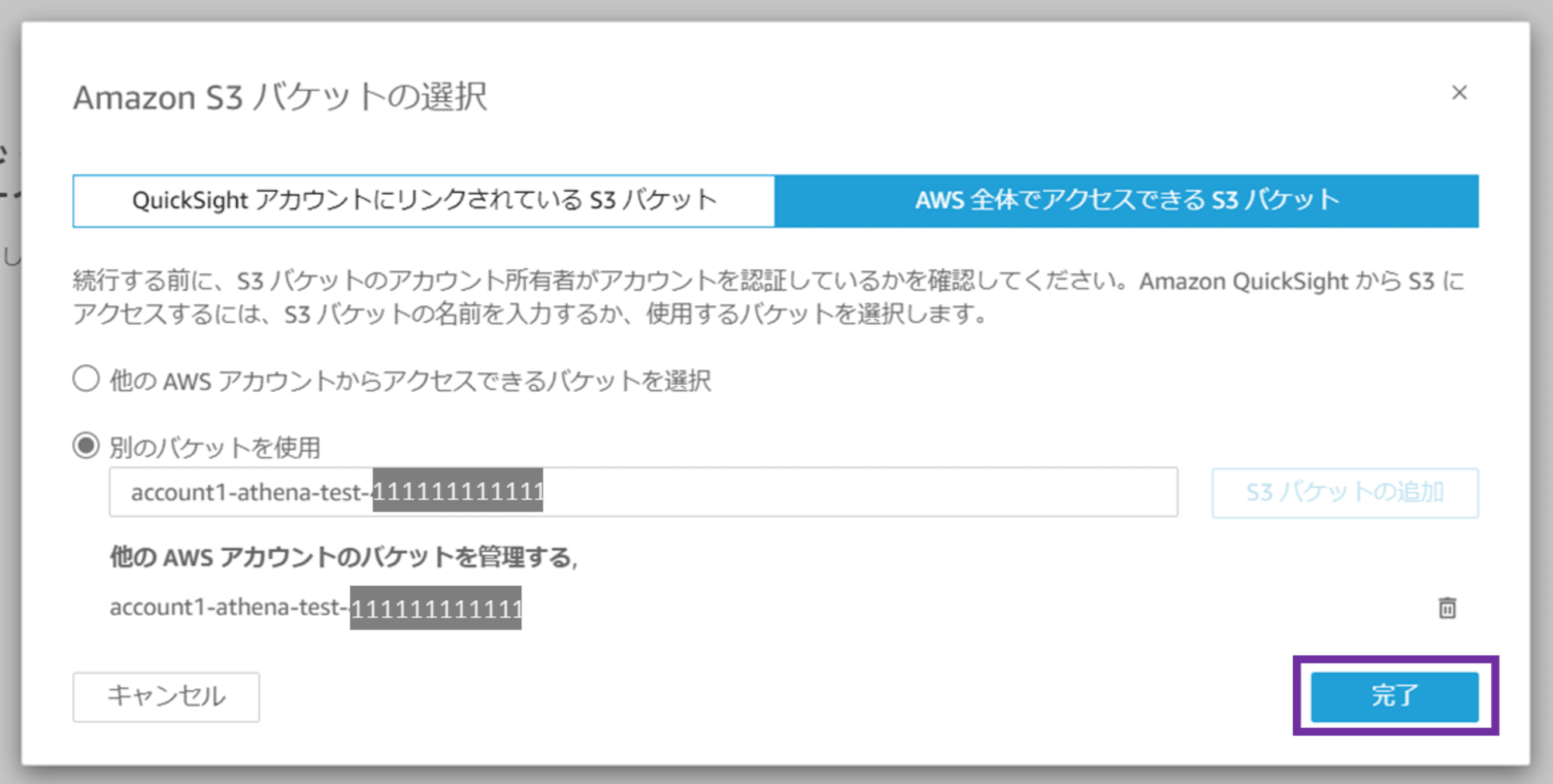
続いて Amazon Athena にチェックします。
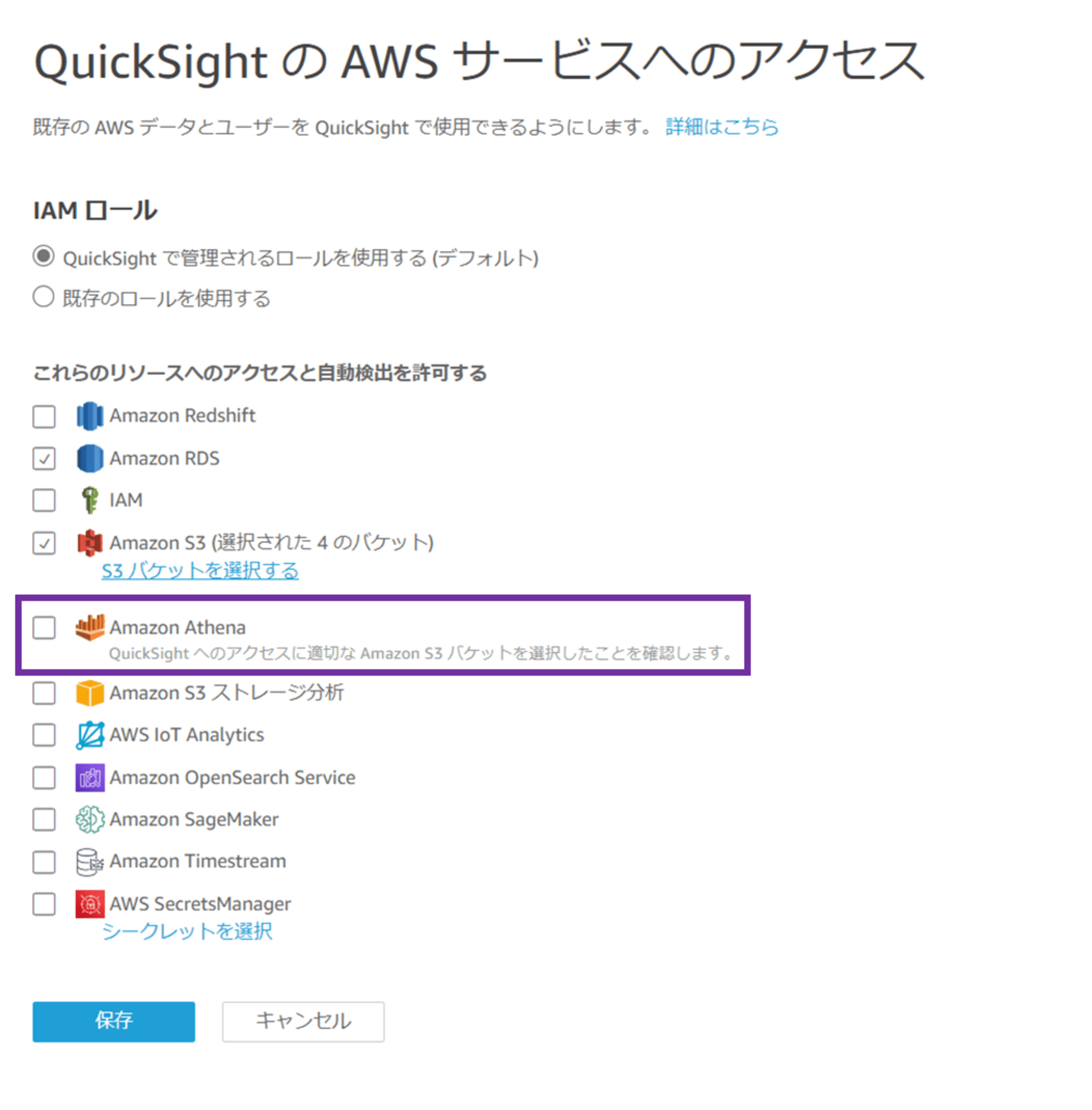
Amazon Athena にチェックすると、「Amazon Athena のアクセス許可 QuickSight に、Athena が使用する Amazon S3 バケットまたは AWS Lambda 関数へのアクセス許可が必要です」というポップアップが出ます。「次へ」をクリックします。
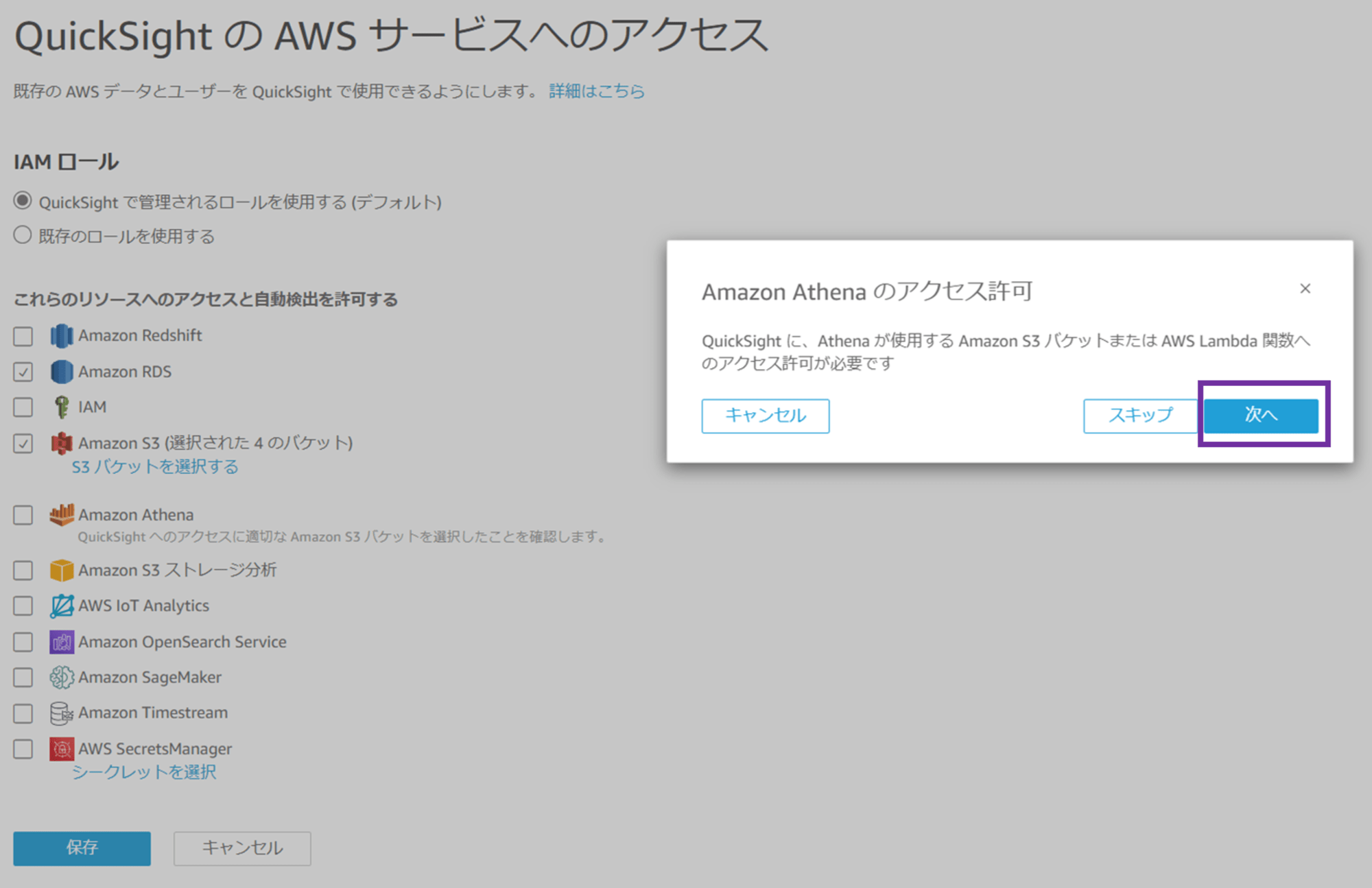
再び S3 バケットの選択画面が出ます。先ほどの S3 選択画面で Athena のクエリ結果保存用 S3 バケットはチェック済みなので、このまま「完了」をクリックします。
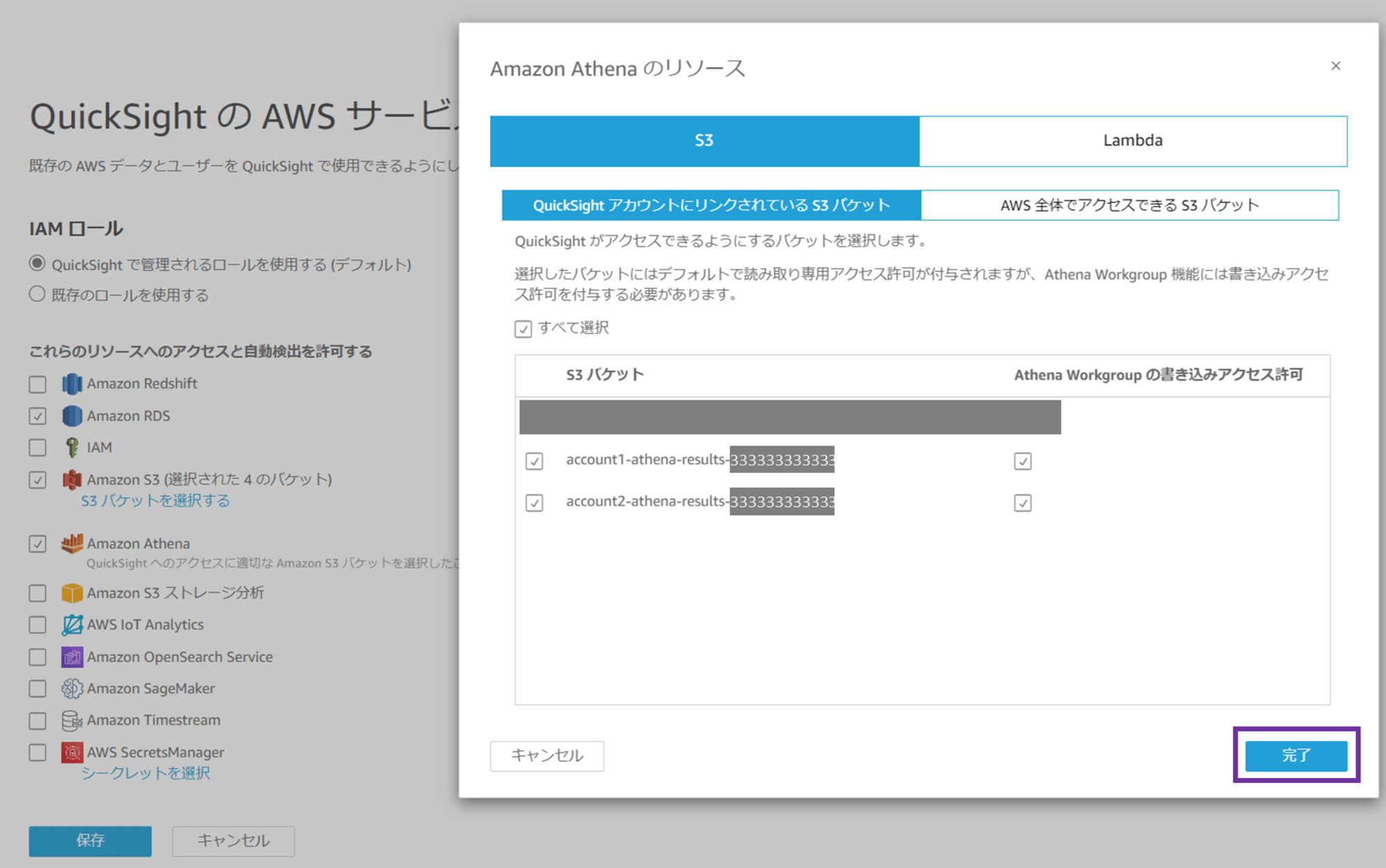
Amazon S3 と Amazon Athena にチェックが入っていることを確認し、「保存」をクリックします。
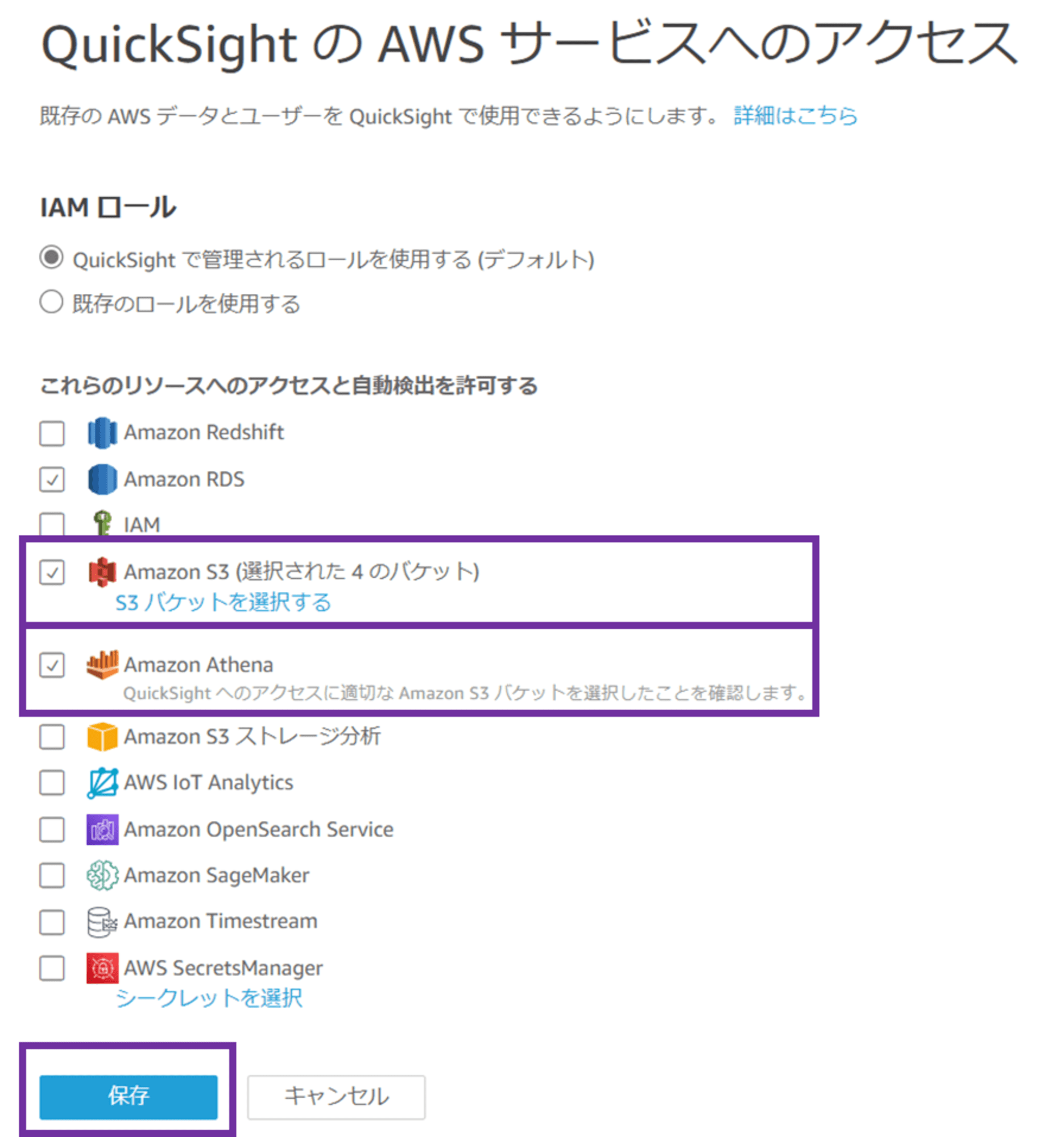
これで QuickSight のアクセス許可設定は完了です。画面左上の QuickSight のロゴをクリックして、QuickSight コンソールに戻ります。
2-2. QuickSight データセットの作成
メニューから「データセット」を選択し、「新しいデータセット」をクリックします。
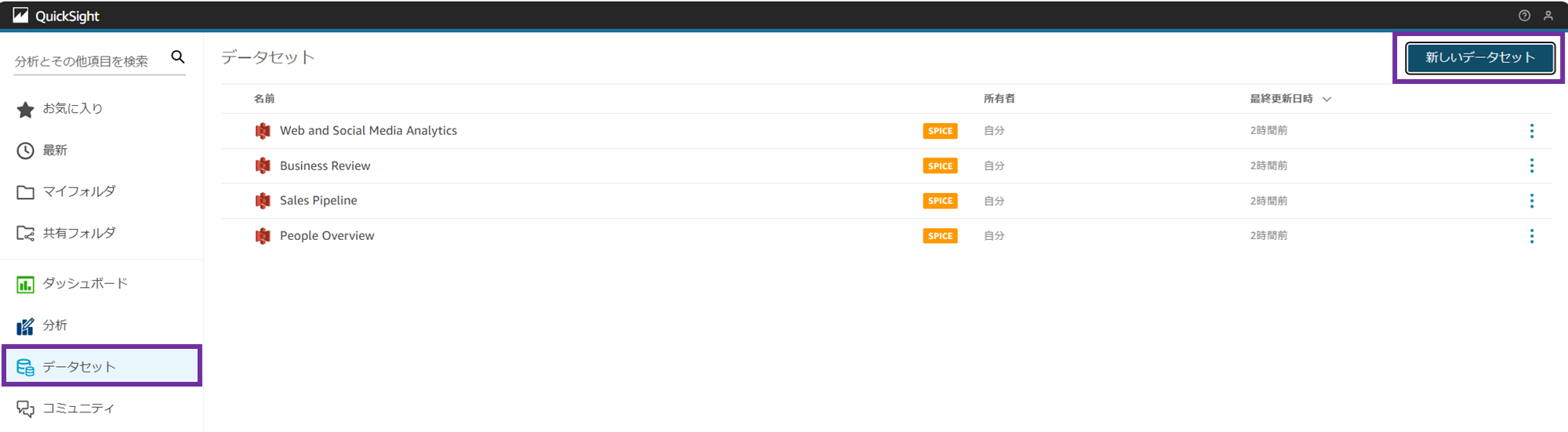
データソースとして Athena を選択します。
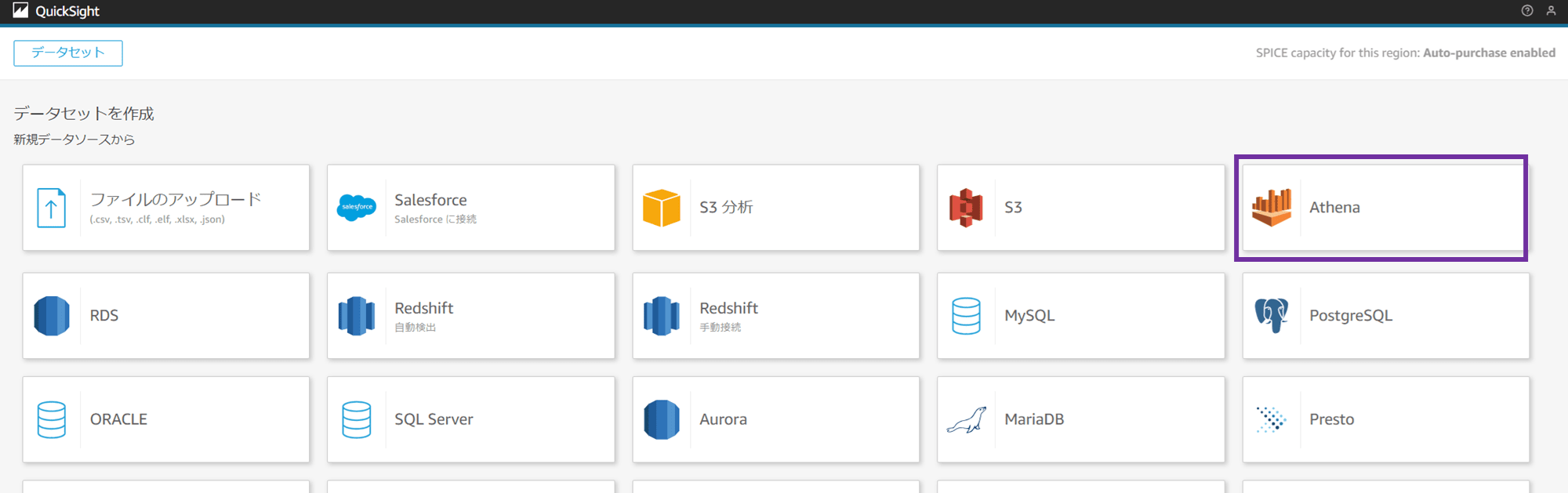
「新規 Athena データソース」のポップアップが出ます。データソース名を設定し、作成した Athena ワークグループを選択します。
- データソース名:account1-sales-data
- Athena ワークグループ:workgroup-account1
「接続を検証」をクリックします。
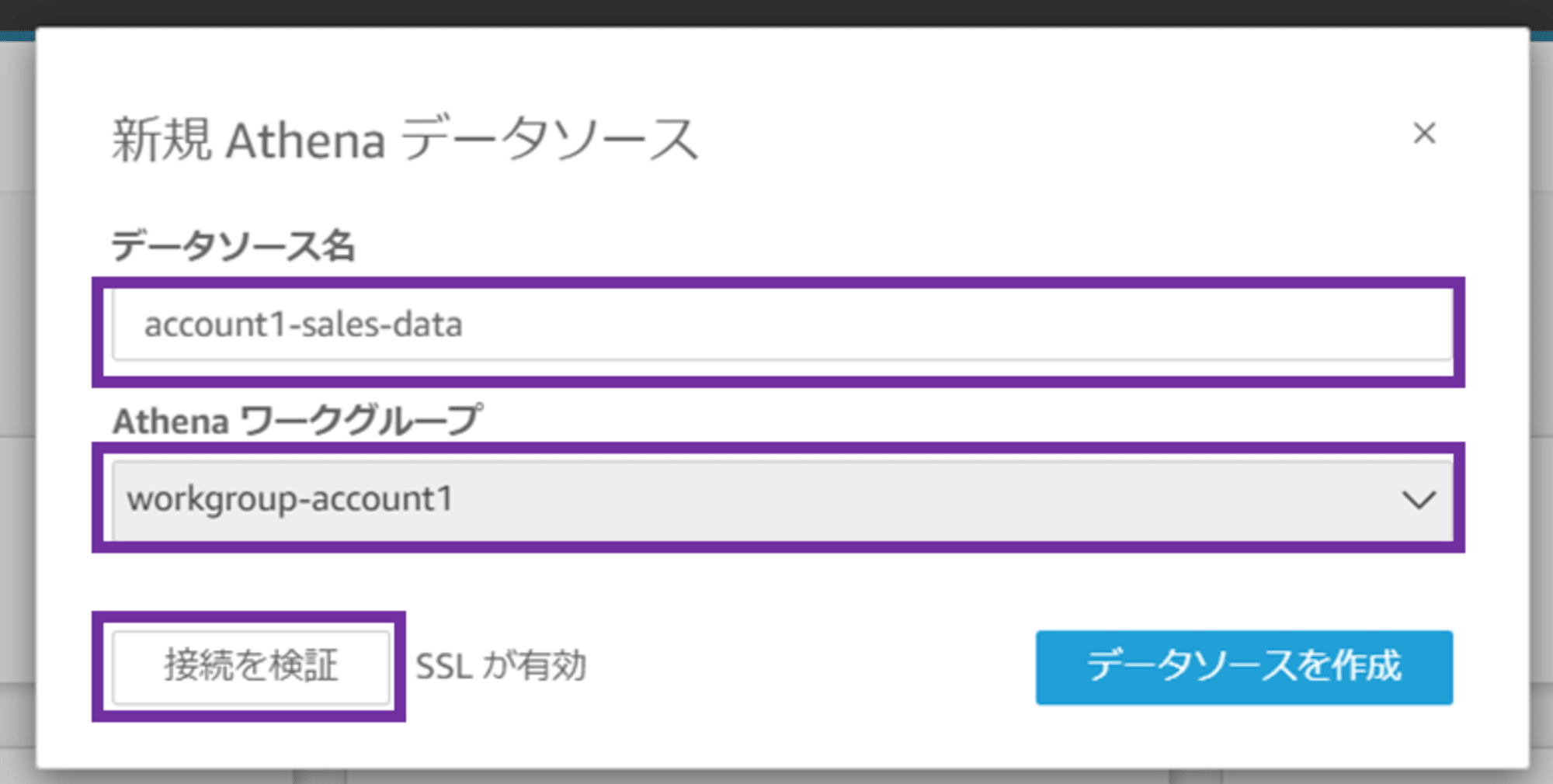
「検証済み」と表示されたら、「データソースを作成」をクリックします。
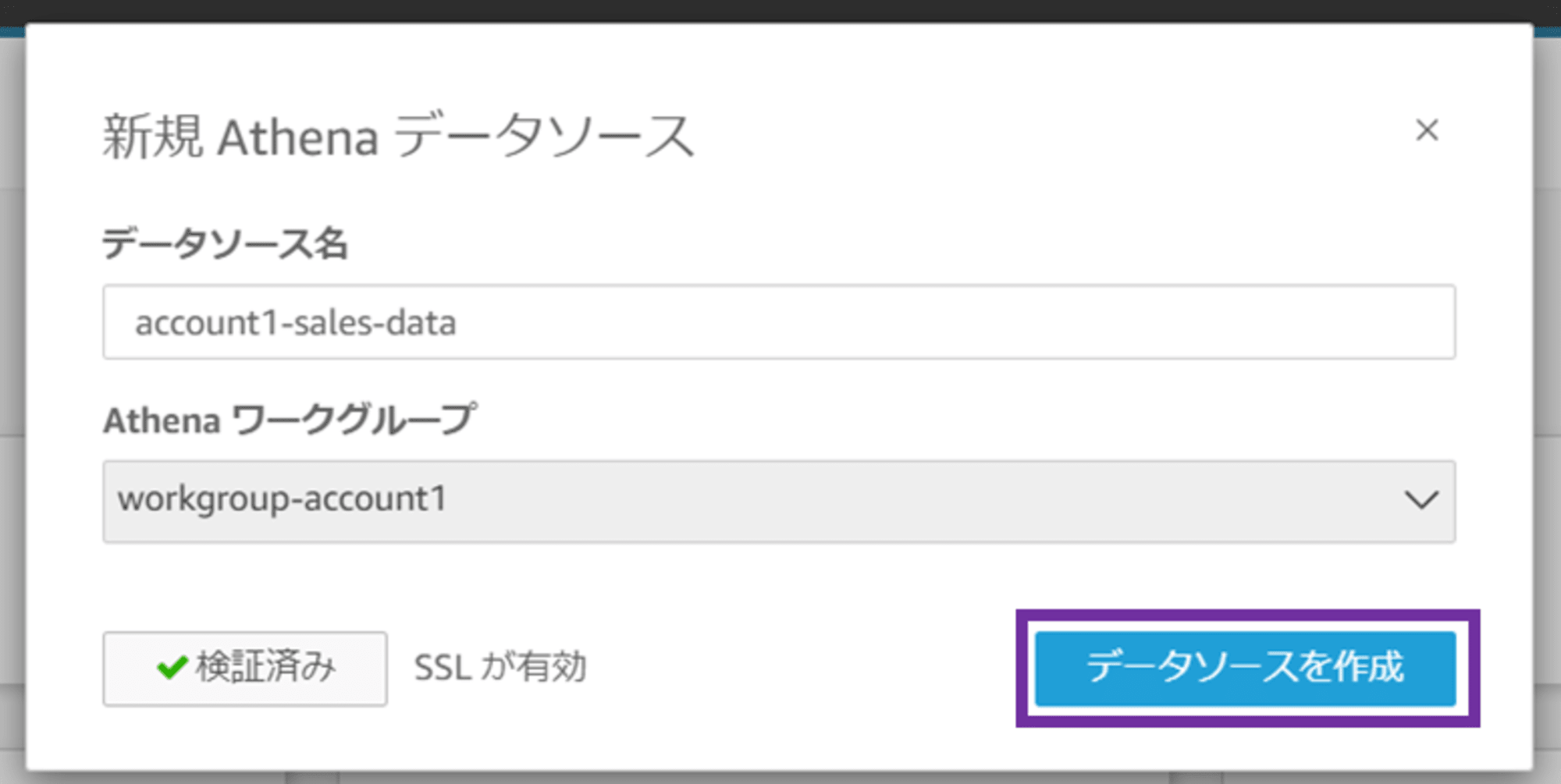
「テーブルの選択」画面に遷移します。データカタログ、作成したデータベース、テーブルを指定します。
- カタログ:AwsDataCatalog
- データベース:account1_data
- テーブル:account1_table
「カスタム SQL クエリを使用」をクリックします。
「カスタム SQL クエリの入力」画面に遷移します。任意の SQL クエリ名とクエリの内容を入力します。
- SQL クエリ名:from_account1
SELECT * FROM account1_data.account1_table
WHERE year = 2024 AND month = 01
「データの編集/プレビュー」をクリックします。
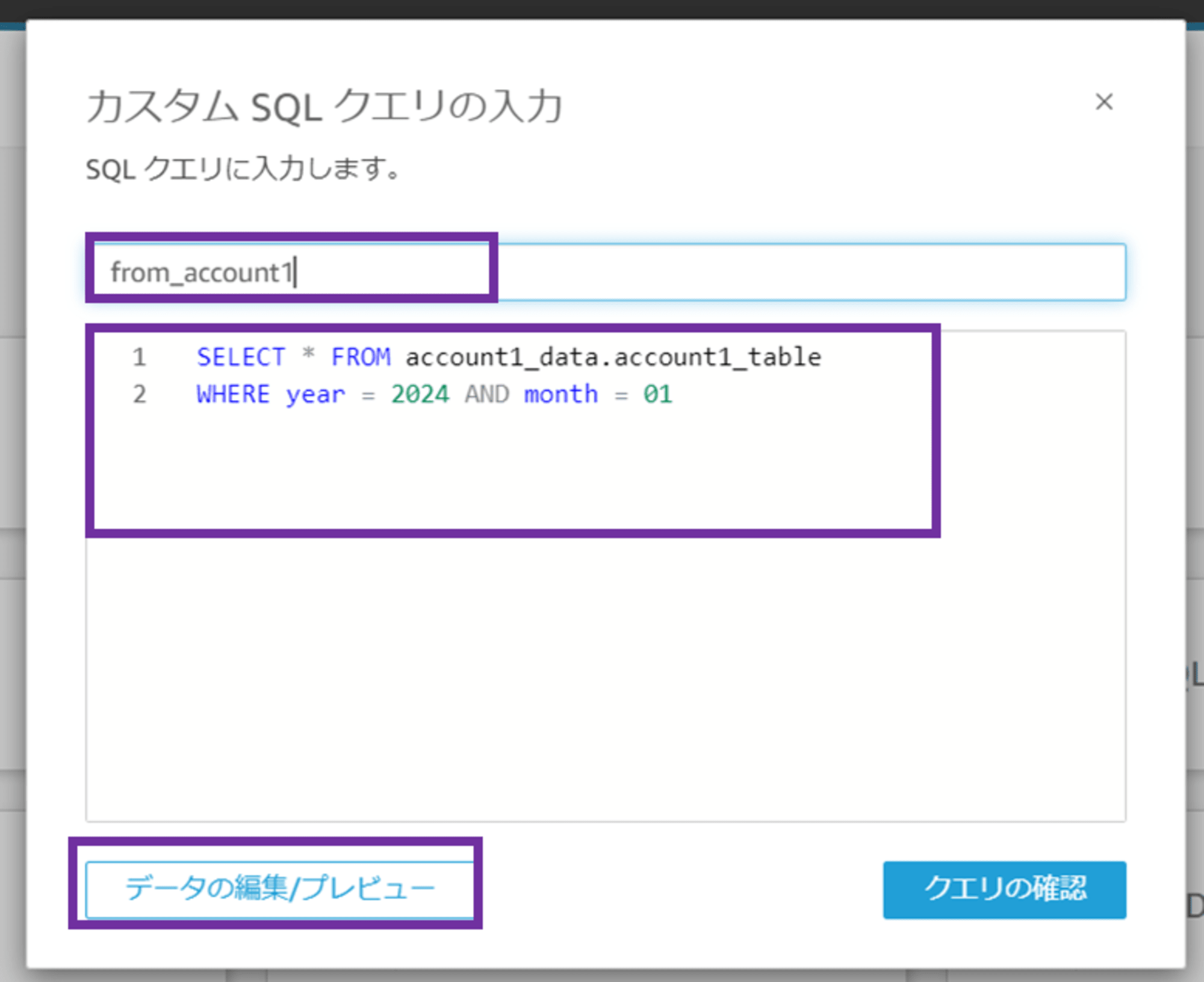
カスタムクエリが入力された状態の画面が開きます。「適用」をクリックすると、QuickSight から Athena を介してワークロードアカウント 1(account 1)の S3 バケットにクエリが発行され、CSV データの中身が画面下部にクエリ結果として表示されます。
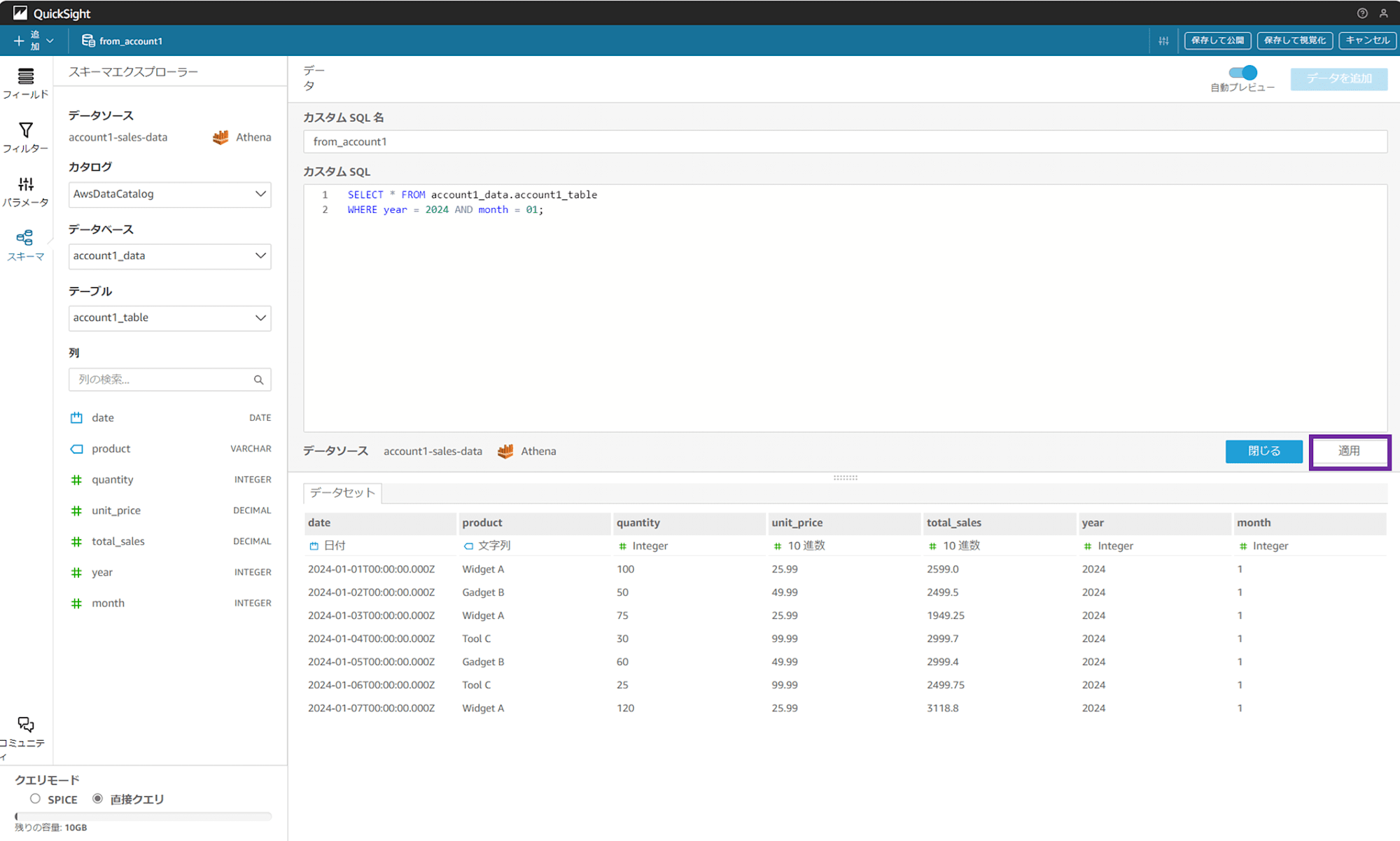
ここまできたら、あとはクエリ結果を可視化するだけです。
画面右上の「保存して視覚化」をクリックし、分析を作成していきます。
2-3. QuickSight 分析の作成
新規シートを作成するポップアップになるので、そのまま「作成」をクリックします。
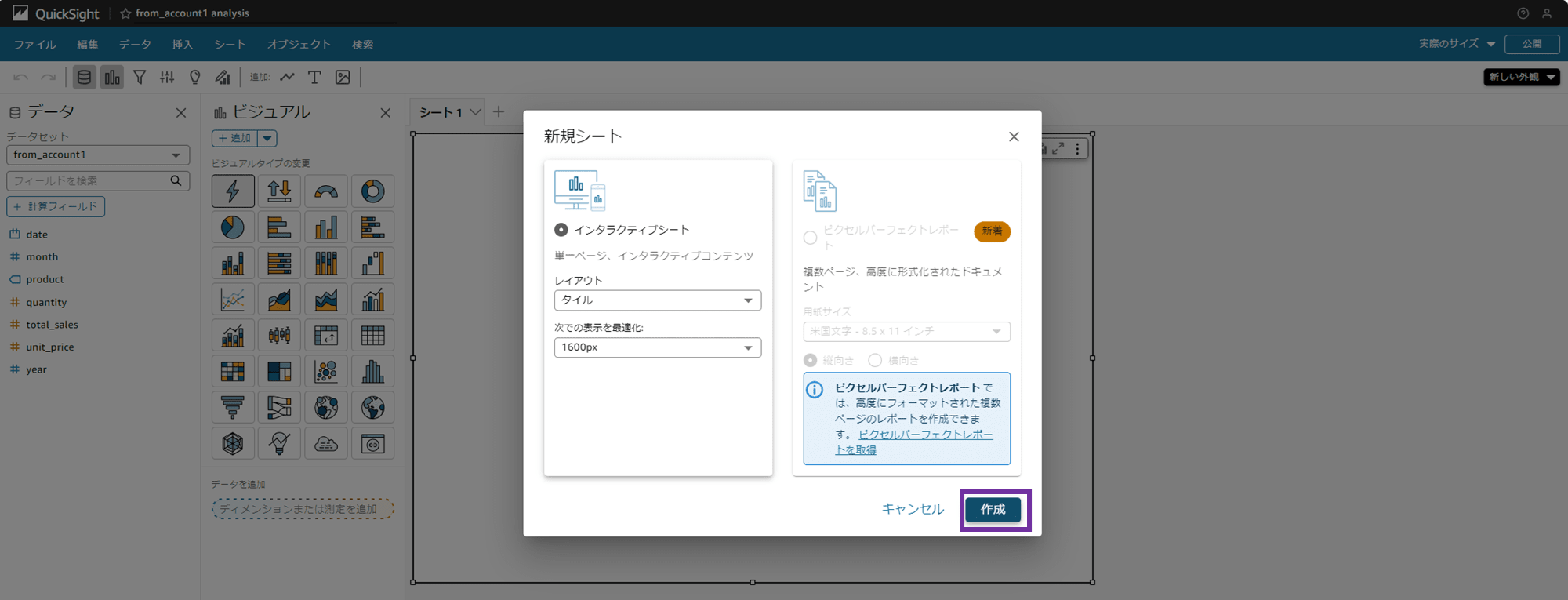
分析が作成され、空のシートが表示されました。
分析の名前は画面左上に表示されているのですが、自動で「from_account1 analysis」となっています。あとから分析名を変更することもできます。
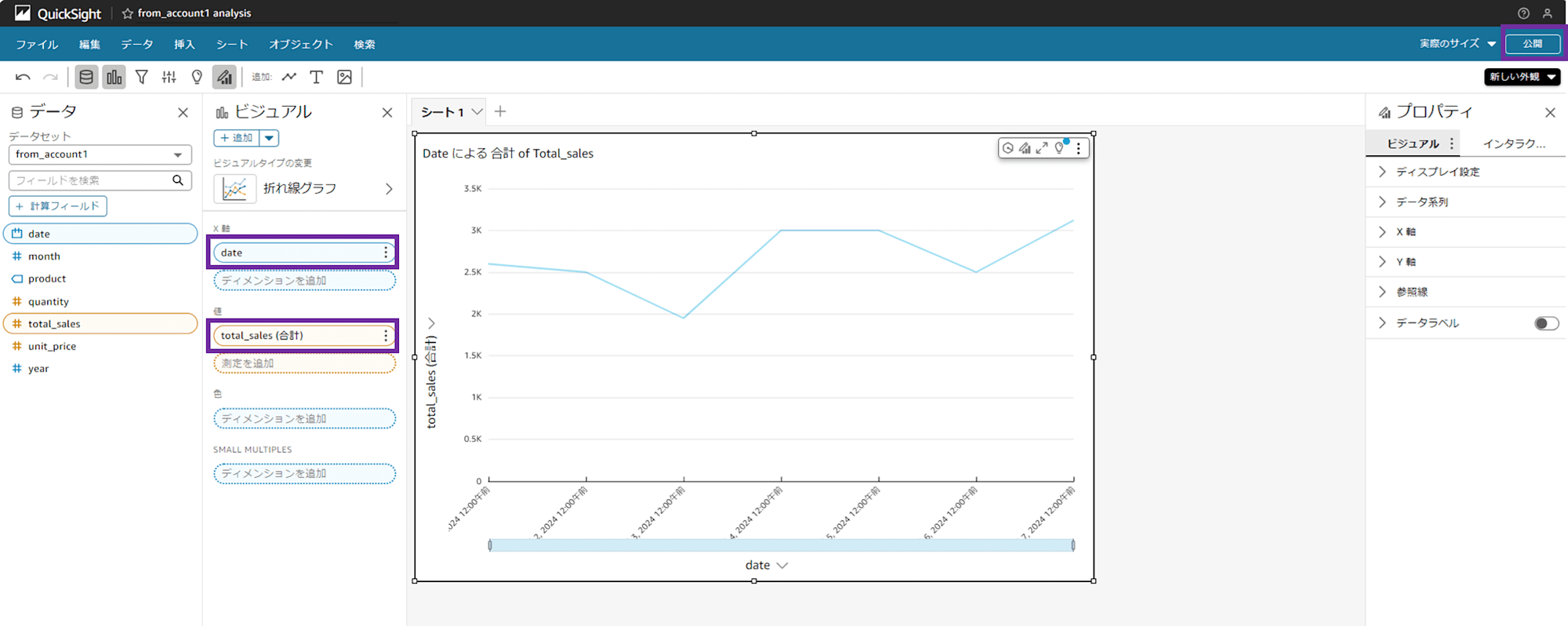
今回は検証なので何でも良いですが、折れ線グラフを選択してみましょう。
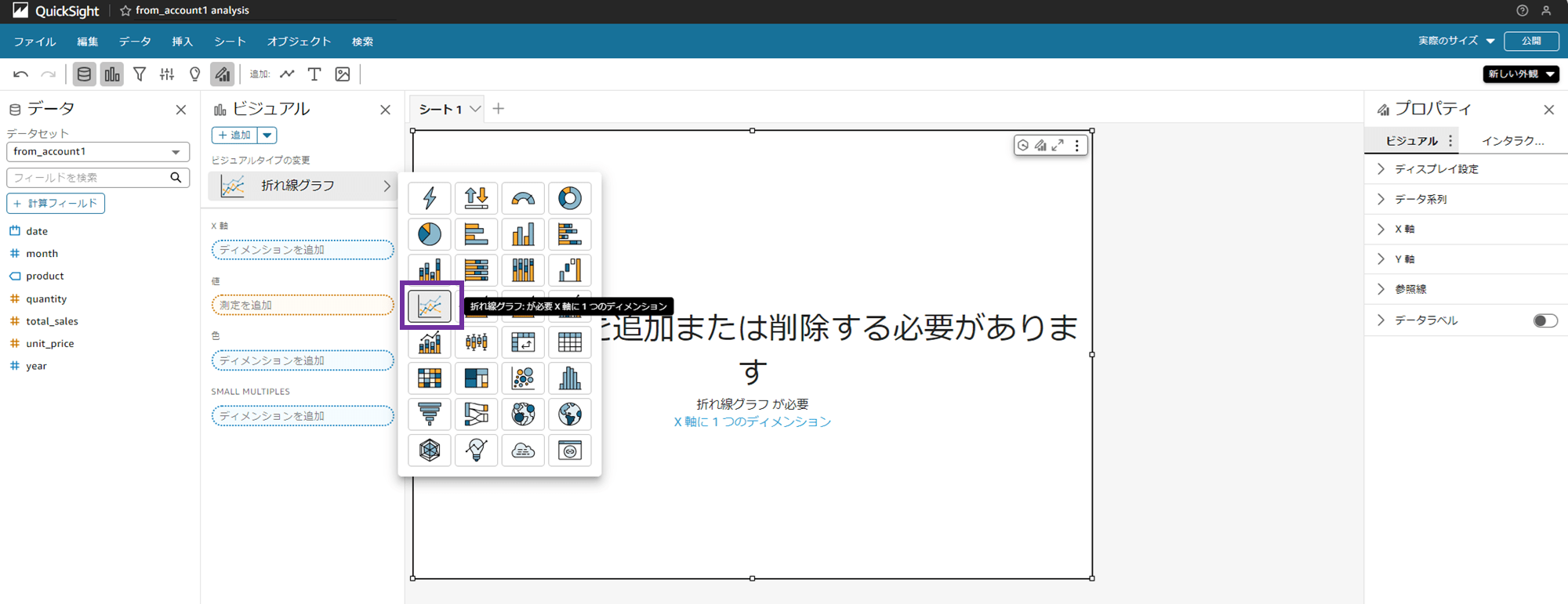
X 軸に「date」、Y 軸に「total_sales」をドラッグアンドドロップすると、折れ線グラフができました。
画面右上の「公開」をクリックして、ダッシュボードを作っていきます。
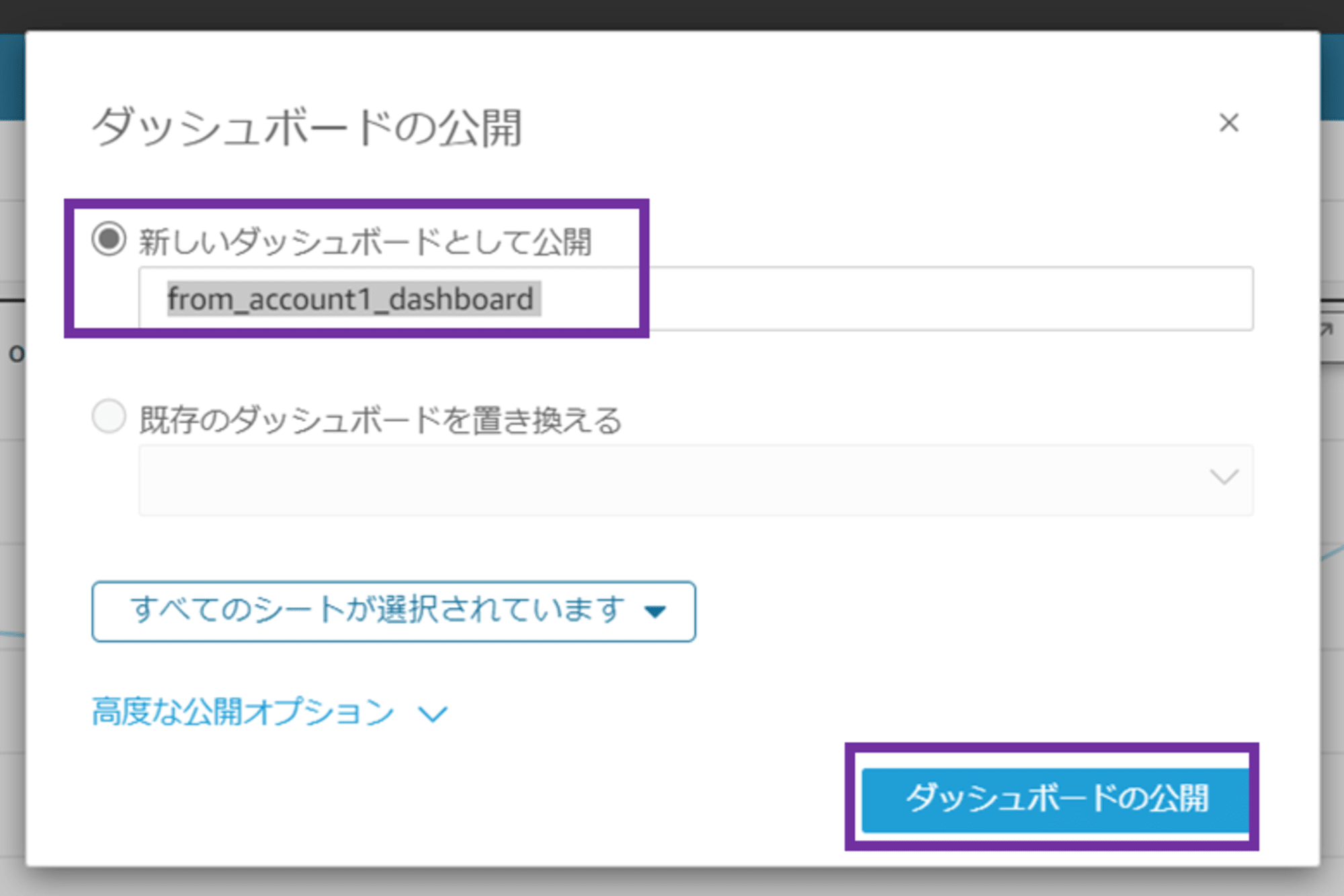
2-4. QuickSight ダッシュボードの作成
「ダッシュボードの公開」ポップアップが出ます。「新しいダッシュボードとして公開」を選択し、任意のダッシュボード名を入力します。
- ダッシュボード名:from_account1_dashboard
公開オプションはデフォルト設定のまま、「ダッシュボードの公開」をクリックします。
ダッシュボードが作成されました。
QuickSight トップ画面に戻ります。
「分析」メニューから、作成した分析「from_account1 analysis」が確認できます。
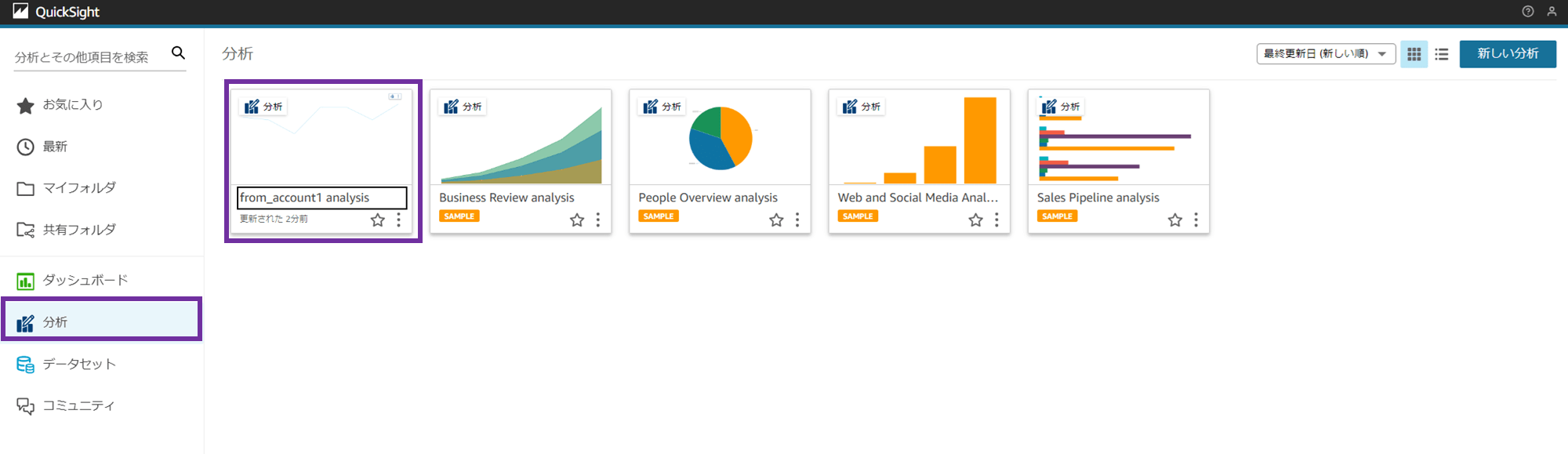
「ダッシュボード」メニューから、作成したダッシュボード「from_account1_dashboard」が確認できます。
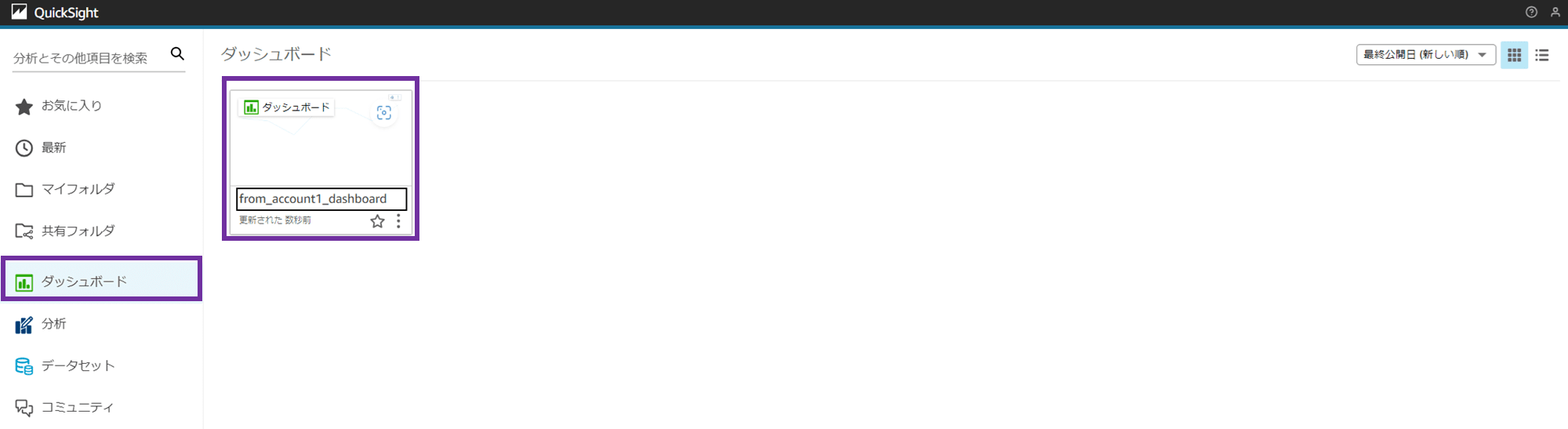
Athena を介して別アカウントの S3 バケットのデータを QuickSight で可視化できました!
account 2 に対しても同様の手順を踏むことで、分析やダッシュボードを作成できます。
元データがある別アカウントの S3 バケットが SSE-KMS で暗号化されている場合
元データがある別アカウントの S3 バケットが SSE-KMS で暗号化されている場合はこちらの re:Post を参考にしてください。
この場合、QuickSight が使う IAM ロールは aws-quicksight-s3-consumers-role-v0 である点に注意が必要です。
Athena データソースをアカウントごとに分けるやり方
検証では Athena のデータソースはデフォルトの「AwsDataCatalog」を複数アカウントに対して併用しました。
Athena データソースをアカウントごとに分けたい場合は、以下ブログの手順を参考にしてみてください。
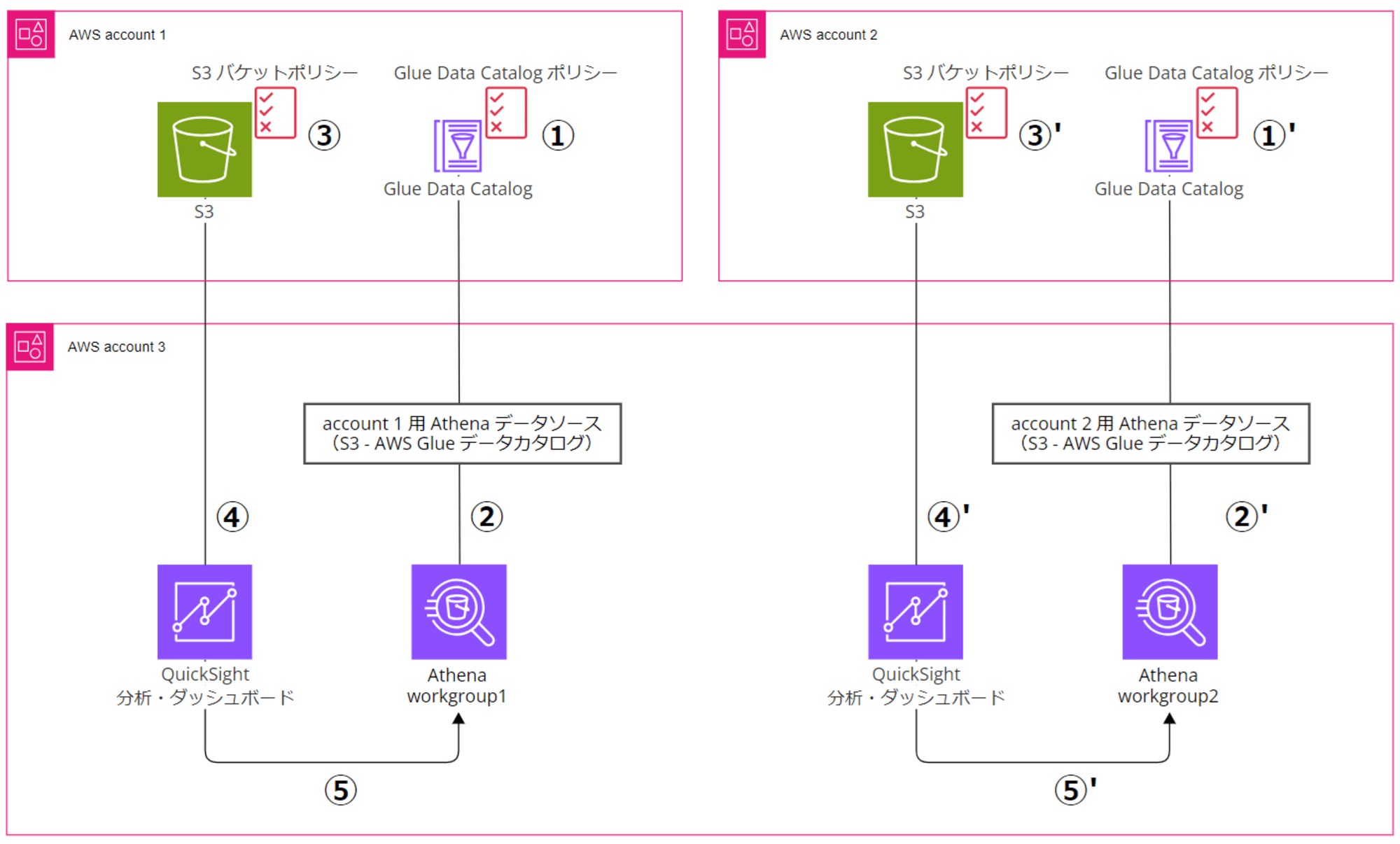
Athena のデータソースを分ける場合は、元データを置く S3 バケットがあるアカウントの方で Glue Data Catalog の作成や Glue 側の許可ポリシーの設定が必要です。
Glue で S3 をクロールしてスキーマを設定する場合はこちらのやり方が良いのかもしれません。手動でのスキーマ設定をコンソールから手動でやるのはちょっと大変そうでした。
終わりに
ひとまず動いて良かったです。様々な許可設定が必要で、可視化するまで悪戦苦闘しました。
- Athena データソースを分ける場合
- Athena ワークグループを分ける場合
- S3 バケットがカスタム KMS キーで暗号化されている場合
…等々でまたパターンが変わってくるかと思います。今回検証してどのパターンで何が必要か薄っすら掴めたので、必要があれば他のパターンでもやってみようと思います。
エラーが出た場合は、
- 許可ポリシーで一旦全部許可をして接続できるか?
- 同じアカウントからなら接続できるか?
などを繰り返し、どこでエラーになっているか根気よく探していくことになるかと思います。
参考








